“Re-ID done right: towards good practices for person re-identification” proposes a different approach to use deep network on person re-identification task. It is on Arxiv yet and the arthors are Jon Almazan, Bojana Gajic, Naila Murray and Diane Larlus from NAVER LABS Europe and UAB.
Summary
- Problem Statement
- Following the success of deep learning, using deep architectures for person re-ID leads to compact global image representations.
- However, there remain many design choices, in particular those related to network architectures, training data, and model training, that have a large impact on the effectiveness of the final person re-ID model.
- Research Objective
- To focus on identify which of desing choices matter for person re-ID
- Proposed Solution
- This paper adopt a different approach that combines a simple deep network with an appropriate training strategy, and whose design choices were both carefully validated on several datasets.
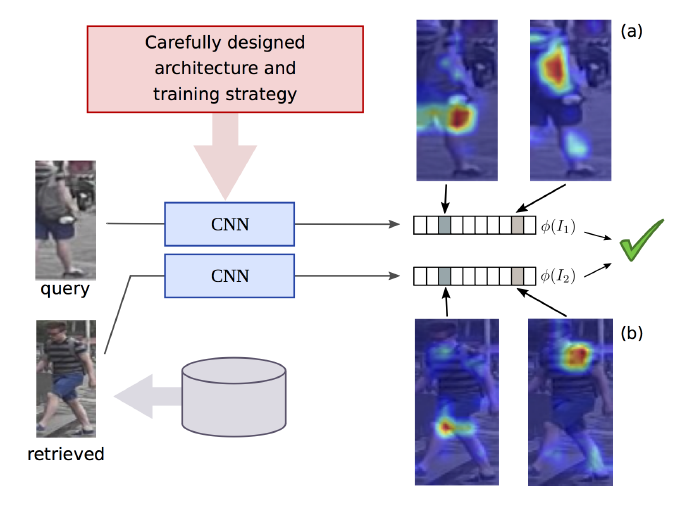 Figure 1: By careful design of deep architecture and training strategy, approach builds global representations that capture the subtle details required for person re-identification by training the embedding dimensions to respond strongly to discriminative regions/concepts such as the backpack or the hem of the shorts. Heatmaps indicate image regions that strongly activate different dimensions of the embedding.
Figure 1: By careful design of deep architecture and training strategy, approach builds global representations that capture the subtle details required for person re-identification by training the embedding dimensions to respond strongly to discriminative regions/concepts such as the backpack or the hem of the shorts. Heatmaps indicate image regions that strongly activate different dimensions of the embedding.
- Contribution
- Identify a set of key practices to adopt, both for representing images efficiently and for training such representations, when developing person re-ID models
- A key conclusion is that curriculum learning is critical for successfully training the image representation and several of this paper’s principles reflect this.
- Proposed method significantly improves over previous published resultson four standard benchmark datasets for person re-identification.
- Provide a qualitative analysis of the information captured by the visual embedding produced by proposed architecture.
- The effectiveness of the model in localizing image regions that are critical for re-ID without the need for explicit attention or alignment mechanisms.
- Identify a set of key practices to adopt, both for representing images efficiently and for training such representations, when developing person re-ID models
Methods
Architecture Design
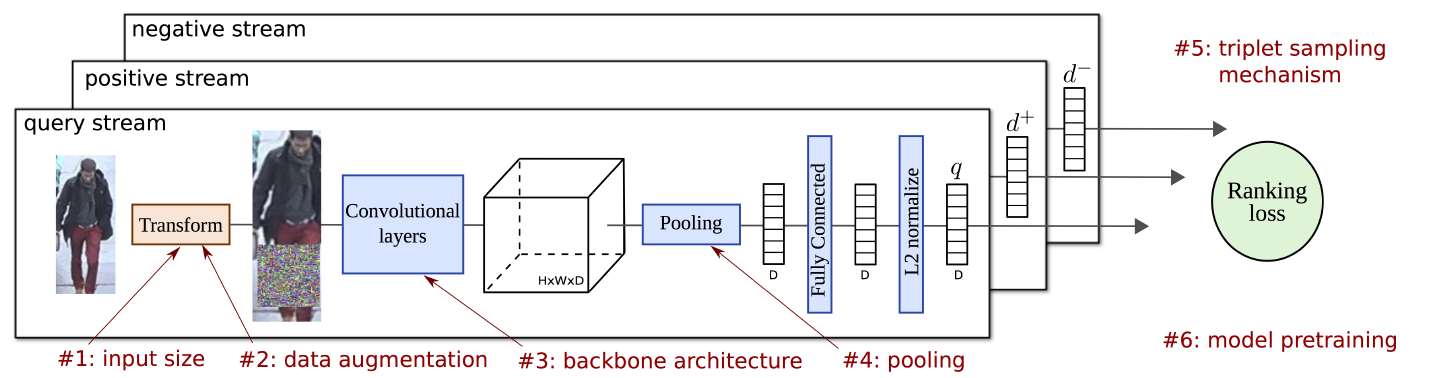
Figure 2: Summary of training approach. Image triplets are sampled and fed to a three stream Siamese architecture, trained with a ranking loss. Weights of the model are shared across streams. Each stream encompasses an image transformation, convolutional layers, a pooling step, a fully connected layer, and an l2-normalization, all these steps being differentiable. In red it shows the steps that require a careful design and that we extensively discuss and evaluate in our paper.
Flow of the architecture
- The model contains a backbone convolutional network, pre-trained for image classification, which is used to extract local activation features from input images of an arbitrary size and aspect ratio.
- These local features are then max-pooled into a single vector, fed to a fully-connected layer and l2-normalized, producing a compact vector whose dimension is independent of the image size.
Backbone networks
- Different backbone CNN can be used interchangeably.
Architecture Training
A key aspect of the representation is that all the operations are differentiable, so all the network weights can be learned in an end-to-end manner.
 Figure 3: Summary of good practices for building a powerful representation for person re-identification.
Figure 3: Summary of good practices for building a powerful representation for person re-identification.
Three-stream Siamese architecture
Let \(I_q\) be a query image with R-MAC descriptor \(q\), \(I^+\) be a relevant image with descriptor \(d+\), and \(I^-\) be a non-relevant image with descriptor \(d^-\), and \(m\) is a scalar that controls the margin. The ranking triplet loss is defined as,
\[L(I_q,I^+,I^-)=\frac{1}{2}\max(0,m+\parallel q-d^+ \parallel ^2 - \parallel q - d^-\parallel ^2)\]Image size
Typically, training images are processed in batches and therefore resized to a fixed input size, which leads to distortions. This paper argue that images should be upscaled to increase the input image size, and that they should not be distorted. To this end, this paper processes triplets sequentially, allowing a different input size for each image and allowing the use of high resolutions images. To account for the reduced batch size, the authors accumulate the gradients of the loss with respect to the parameters of the network for every triplet, and only update the network once they achieve the desired effective batch size.
Pretraining
The authors use pretrained networks on ImageNet, perform additional pre-training step by fine-tuning the model on the training set and then train the model with rank loss.
Data augmentation
- Used “cut-out” strategy, which consists of adding random noise to random-sized regions of the image.
- Progressively increase the maximum size of the regions during training, progressively producing more difficult examples.
- It targets robustness to occlusion and allows for model regularization by acting as a “drop-out” at the image level.
- Tried to use “flipping” and “cropping” but found no added improvement
Hard triplet mining
Training with a triplet loss can lead to underwhelming results, so this paper use mining hard triplets for learning.
Curriculum Learning for re-ID
It has been shown that curriculum learning, which is learning a set concepts more easily when the concepts to be learned are presented by increasing degree of complexity, has a positive impact on the speed and quality of the convergence of deep neural networks. This paper used three different curriculum learning design: hard-negative mining strategy, pre-training strategy, and training with cut-out.
Experiments
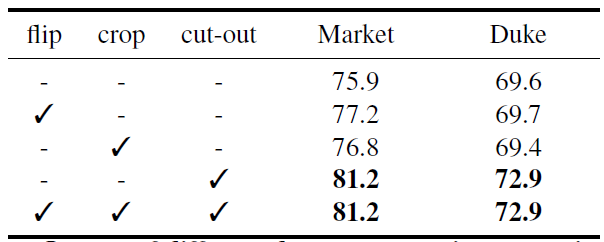 Figure 4: Impact of different data augmentation strategies. It reports mean average precision (mAP) on Market and Duke.
Figure 4: Impact of different data augmentation strategies. It reports mean average precision (mAP) on Market and Duke.
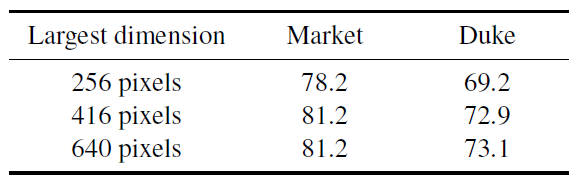 Figure 5: Impact of the input image size. We report mean average precision (mAP) on Market and Duke.
Figure 5: Impact of the input image size. We report mean average precision (mAP) on Market and Duke.
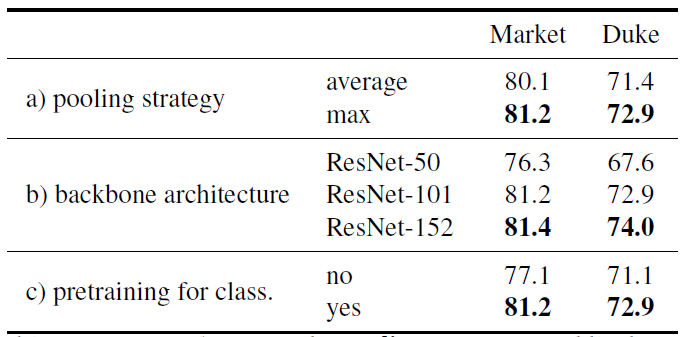 Figure 6: Top (a): influence of the pooling strategy. Middle (b): results for different backbone architectures. Bottom (c): influence of pretraining the network for classification before considering the triplet loss. We report mAP for Market and Duke.
Figure 6: Top (a): influence of the pooling strategy. Middle (b): results for different backbone architectures. Bottom (c): influence of pretraining the network for classification before considering the triplet loss. We report mAP for Market and Duke.
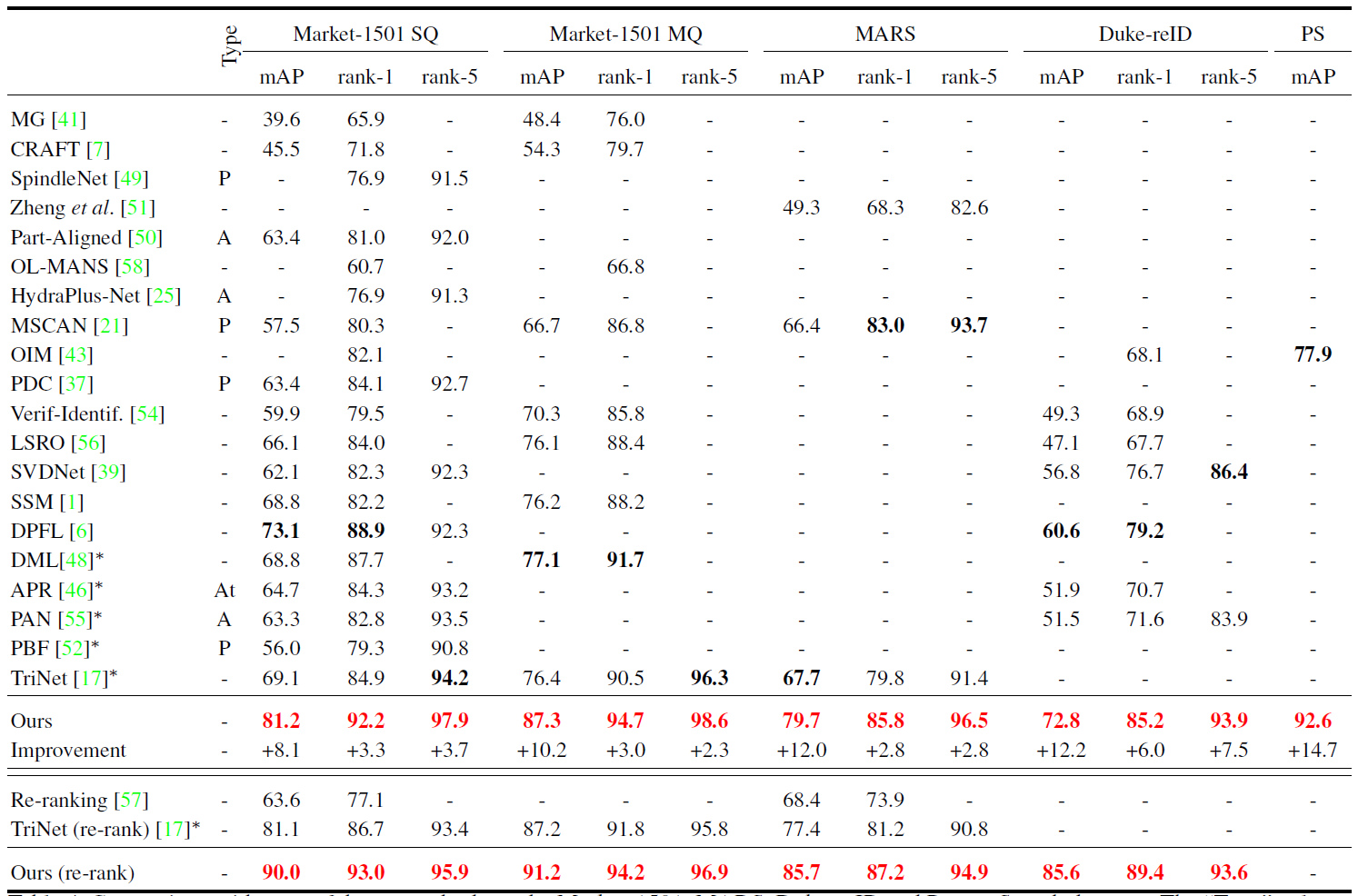
Figure 7: Comparison with state of the art methods on the Market-1501, MARS, Duke-reID and Person Search datasets. The “Type” column indicates methods that include the following additional components: a part-based representation (P) with extra annotations, an attention mechanism (A), or attribute annotations at train time (At). Bold numbers show the current state of the art, while red numbers correspond to the best number overall.
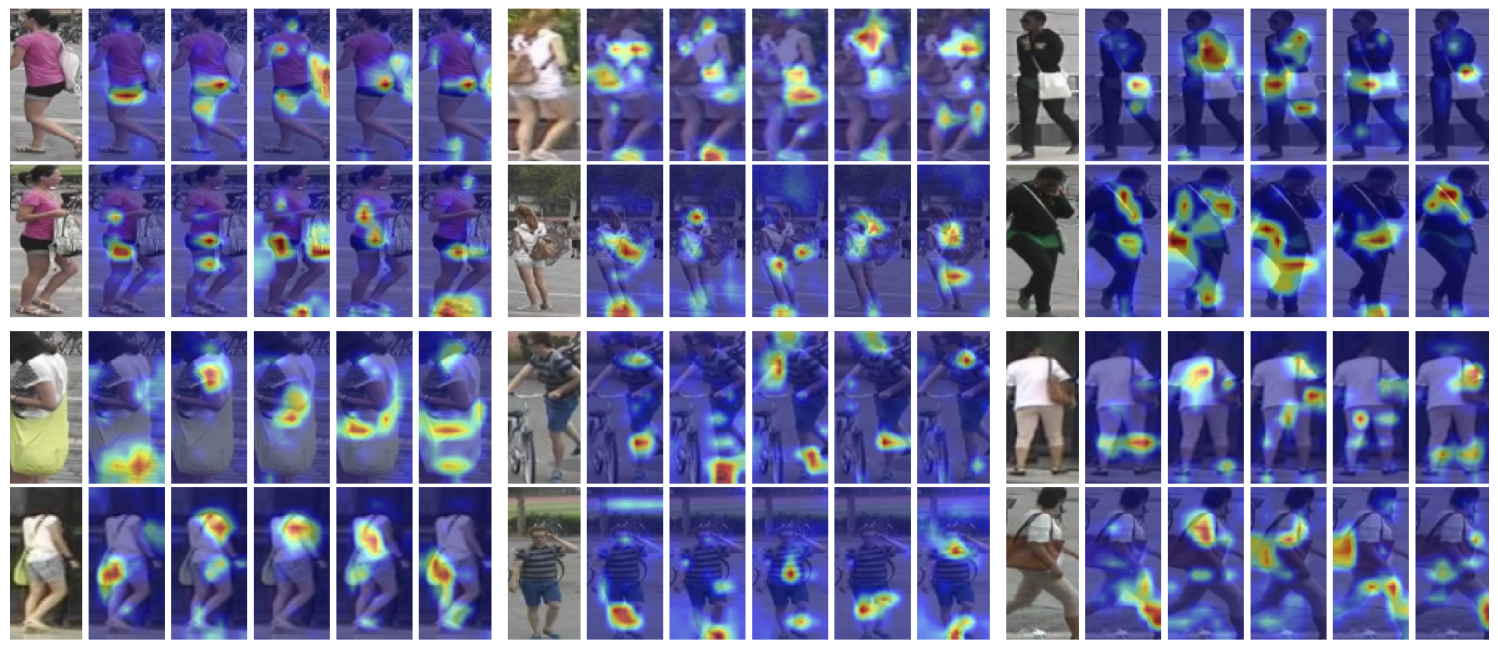
Figure 8: Matching regions For pairs of matching images, we show maps for the top 5 dimensions that contribute most to the similarity.
References
- Paper: Re-ID done right: towards good practices for person re-identification, Arxiv2018



