“Mining Objects: Fully Unsupervised Object Discovery and Localization From a Single Image” focus on performing unsupervised object discovery and localization in a strictly general setting where only a single image is given.
Summary
- Problem Statement
- Performing unsupervised object discovery and localization in a single image is challenge compared to typical co-localization or weakly-supervised localization tasks
- Goal
- To discover dominant objects without using any annotations.
- Proposed Solution
- Propose a simple but effective pattern mining-based method, called Object Mining (OM), which exploits the advantages of data mining and feature representation of CNNs.
- OM converts the feature maps from a pretrained CNN model into a set of transactions, and then frequent patterns are discovered from transaction database through pattern mining techniques.
- We observe that those discovered patterns, i.e., co-occurrrence highlighted regions, typically hold appearance and spatial consistency.
- Motivated by this observation, we can easily discover and localize possible objects by merging relevant meaningful patterns in an unsupervised manner.
- Contribution
- We observe that the frequently-occurring patterns in CNN feature maps strongly correspond to the spatial cues of objects. Such simple observation leads to an effective unsupervised object discovery and localization method based on pattern mining techniques, named Object Mining (OM).
- We propose an efficient transaction creation strategy to transform the convolutional activations into transactions, which is the key issue for the success of pattern mining techniques.
- Extensive experiments are conducted on four finegrained datasets, Object Discovery dataset, ImageNet subsets and PASCAL VOC 2007 dataset. Proposed method outperforms other fully-unsupervised methods by a large margin. Compared with co-localization methods, OM achieves competitive performance even for oone single image in an unsupervised setting.
Object Mining

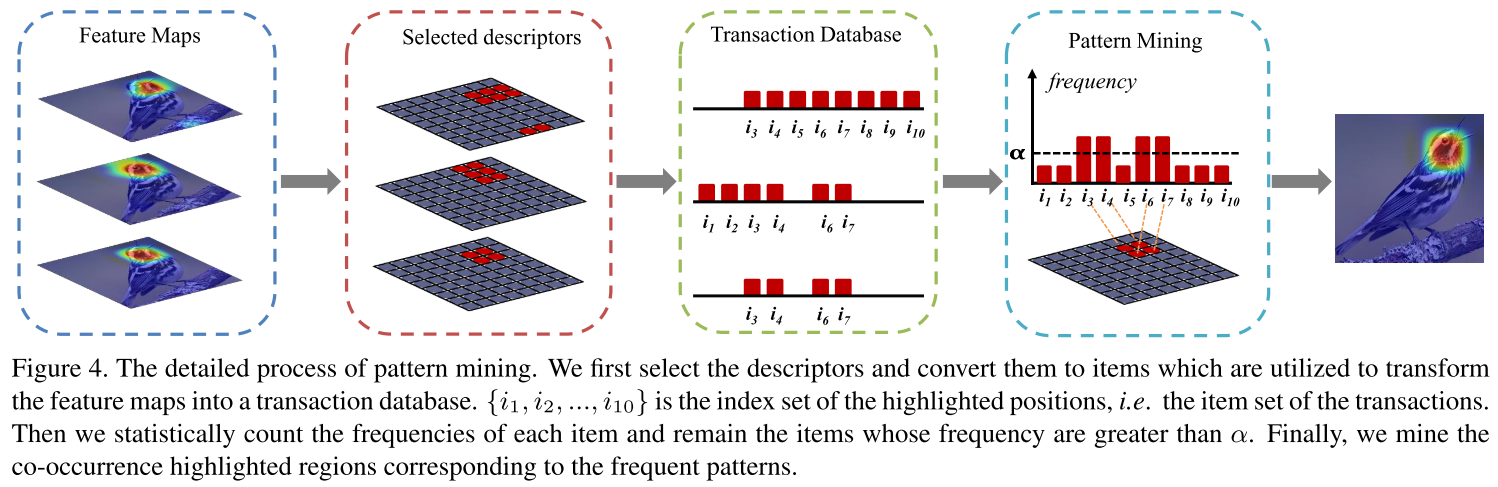
- Extract the feature maps from the Pool-5 and ReLU-5 layers of a pre-trained VGG-16 model.
- The reason adpoting the multi-layer combination is that such strategy allows to take original images with arbitrary sizes as input, and also alleviates the loss of useful information caused by only considering single layer activations.
- The feature maps are converted into a set of transactions.
- Resize Pool-5 feature maps to the same size with ReLU-5 by bilinear interpolation.
- Calculate the mean value \(\beta\) of the activation responses larger than 0 as the tunable threshold.
- The position whose response magnitude is higher than \(\beta\) is highlighted and the index will be converted intot an item.
- The meaningful patterns are discovered by pattern mining techniques.
- Apply the Apriori algorithm to find the frequent items.
- The support threshold determines which patterns would be mined.
- Merge the selected patternes to localize potential target regions.
- Use Spatial continuity to select the optimal patterns for object localization.
- It select the largest connected component based on the mined patterns.
- To obtain the support map with the same size as the original image, we upsample the support map by bilinear interpolation.
Experiments
Evaluation Metric
We use the correct localization (CorLoc) to evaluate the proposed method. According the PASCAL-criterion, the CorLoc is defined as,
\[\frac{area(B_p \cap B_{gt}) }{area(B_p \cup B_{gt})}>0.5,\]
where \(B_p\) is the predicted box and \(B_{gt}\) is the ground-truth box.
Object Localization
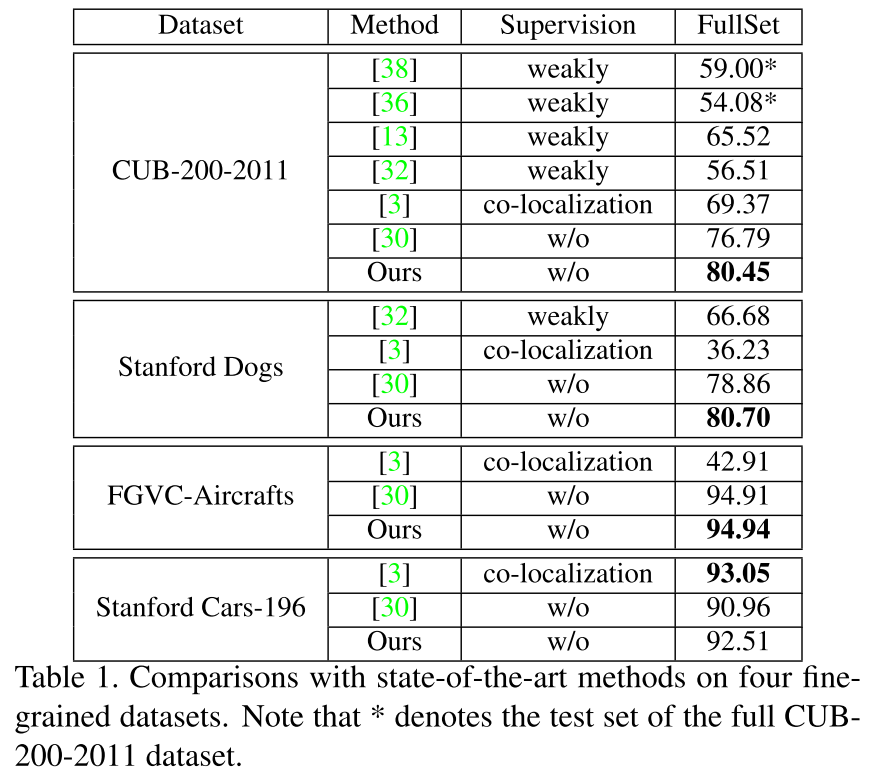
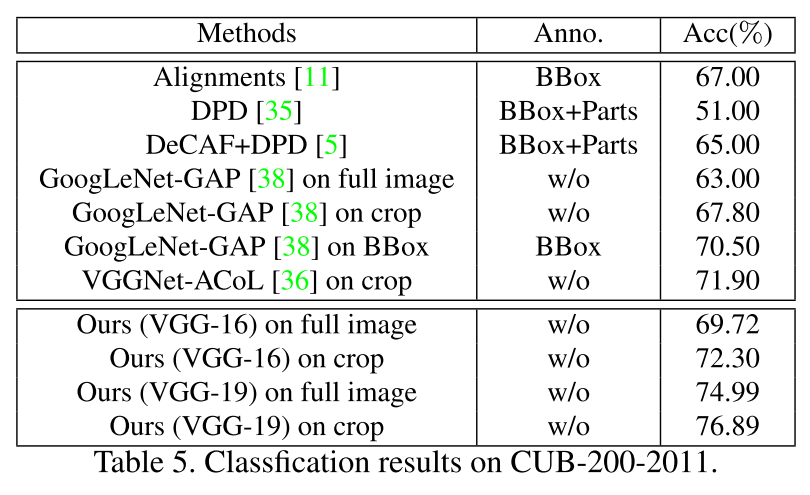

Computational Complexity
- Environments
- Randomly select 400 images from the CUB-200-2011 datasets
- Intel Xeon E5-2683 v3, 128G main memory
- A TITAN Xp GPU
- OM approach consists of two major steps:
- (1) feature extraction
- (2) pattern mining-based object localization including transaction creation, pattern mining, and support map generation.
- Computational Time
- The execution time for feature extraction is about 0.03 sec/image (33.3 fps) on GPU and 0.74 sec/image (1.35 fps) on CPU, respectively.
- The second step only takes about 0.21 sec/image (4.762 fps) both on GPU and CPU.
- Thus, the execute time is totally about 0.24 sec/image (4.17 fps) on GPU and 0.95 sec/image (1.05 fps) on CPU, respectively.