Today, I am going to introduce interesting project, which is ‘Multi-Speaker Tacotron in TensorFlow’. It is a speech synthesis deep learning model to generate speech with certain person’s voice. For the example result of the model, it gives voices of three public Korean figures to read random sentences.
Speech Synthesis
Speech synthesis is the artificial production of human speech from plain text. Especially, a text-to-speech (TTS) system converts plain language text into speech and the it has been becomming more natural and human-like voice from the cold and machine-like voice.
Research on speech synthesis by deep learning became one of the hottest topic as the market of AI increases. The technique can be used on lots of application such as conversational AI (Siri, Bixby), audio book and audio guidance system (navigation, subway).
Multi-Speaker Tacotron
The project ‘Multi-Speaker Tacotron’ combined two different models, Tacotron and Deep Voice 2.
Tacotron
Tacotron is a research on speech synthesis from Google, introduced in 2017. It is an end-to-end generative text-to-speech model that synthesizes speech directly from characters. By given <text, audio> pairs, the model can be trained completely from scratch with random initialization.
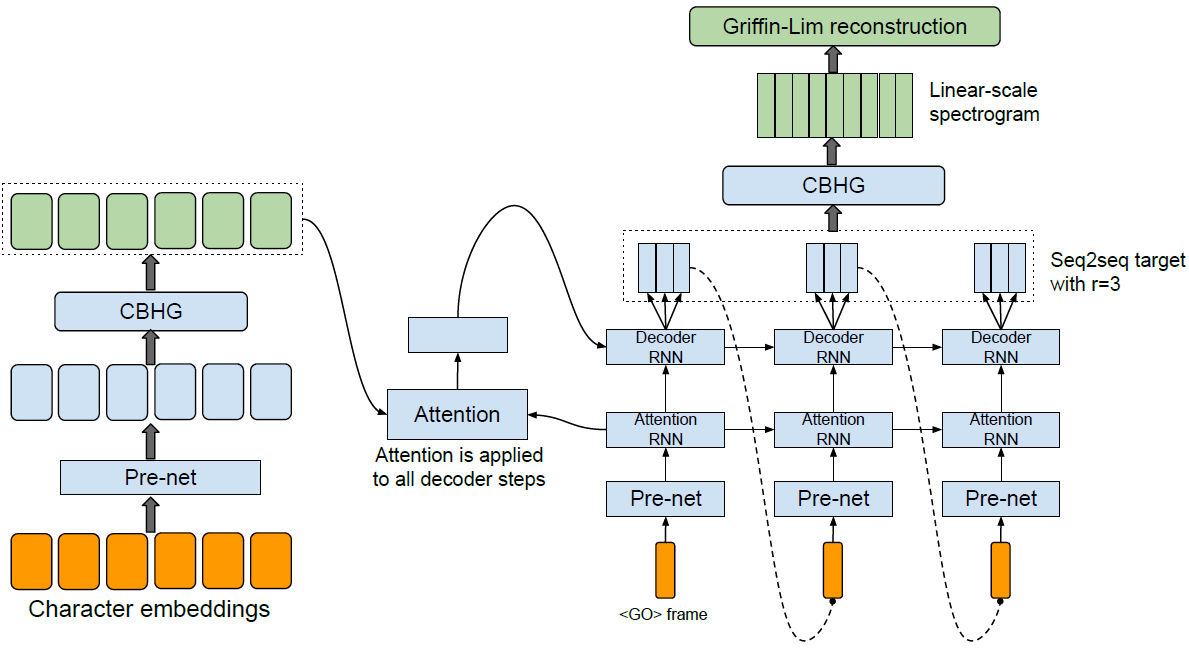
The Tacotron model is consists of four different modules: Encoder, Decoder, Attention, and Vocoder.
1. Encoder
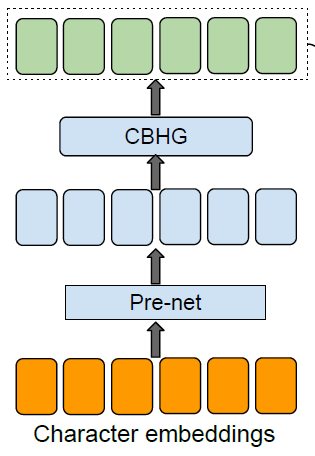
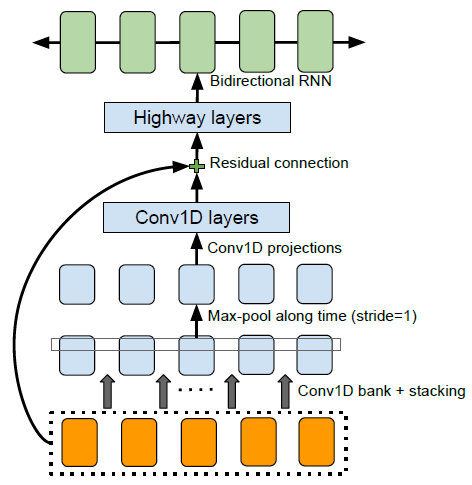
The part of encoder module encode a language text into a vector containing information of the original text. First, the plain language text has to be converted into vectors of real numbers by word embedding. Second, the embedded continuous vector is applied a set of non-linear transformations which is called a “pre-net”. The prenet is consists of FC-256-ReLu -> Dropout(0.5) -> FC-128-ReLU -> Dropout(0.5). Third, a CBHG module transforms the prenet outputs into the final encoder representation used by the attention module. The architecture of CBHG module is described in below figure.
2. Decoder
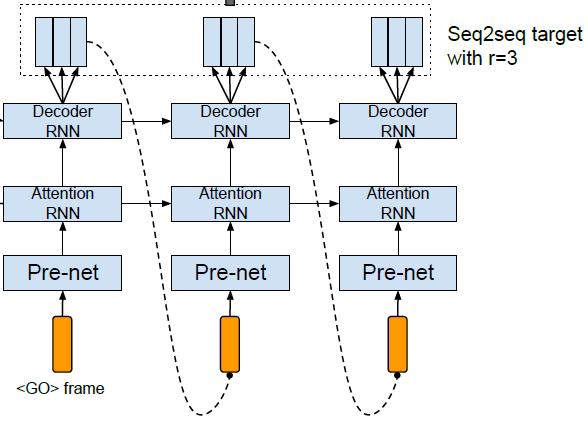
In the part of decoder module, it outputs next step of spectrogram from the previous step of spectrogram by using RNN based decoder. The decoder is a content-based tanh attention decoder, where a stateful recurrent layer produces the attention query at each decoder time step. Spectrogram, which is output of the decoder module, will be used for generating sounds of speech.
3. Attention
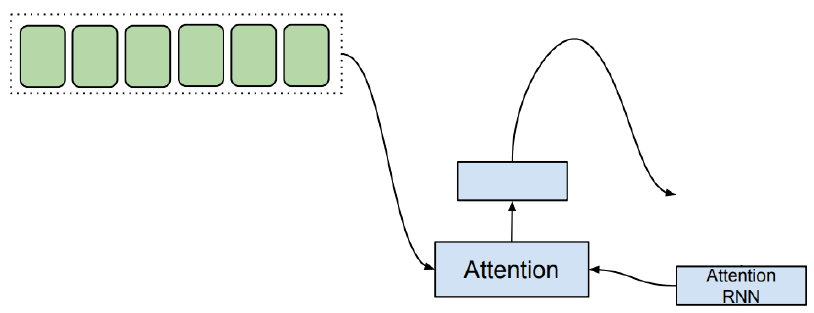
The context vector and the attention RNN is concatenated to each other in order to form the input to the decoder RNNs. And the text analysis and acoustic modeling are accomplished together by an attention based RNN, which has the capacity to learn the relevant contextual factors embedded in the text sequence. This helps to generate more natural and human-like speech from a language text which is not trained before.
4. Vocoder
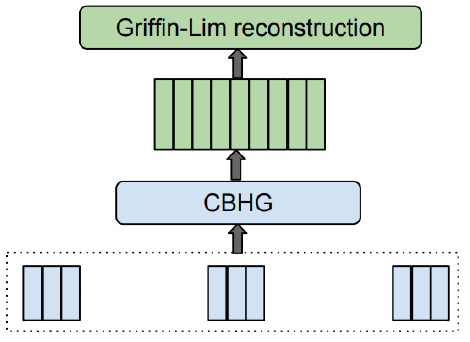
The output spectrogram from the decoder module will go through a CBHG module for the post-processing net which is used to predict alternative targets such as vocoder parameters that synthesizes waveform samples directly. And then, the Griffin-Lim reconstruction process will be used to synthesize waveform from the predicted spectrogram. These process finally outputs sounds of speech.
Deep Voice 2
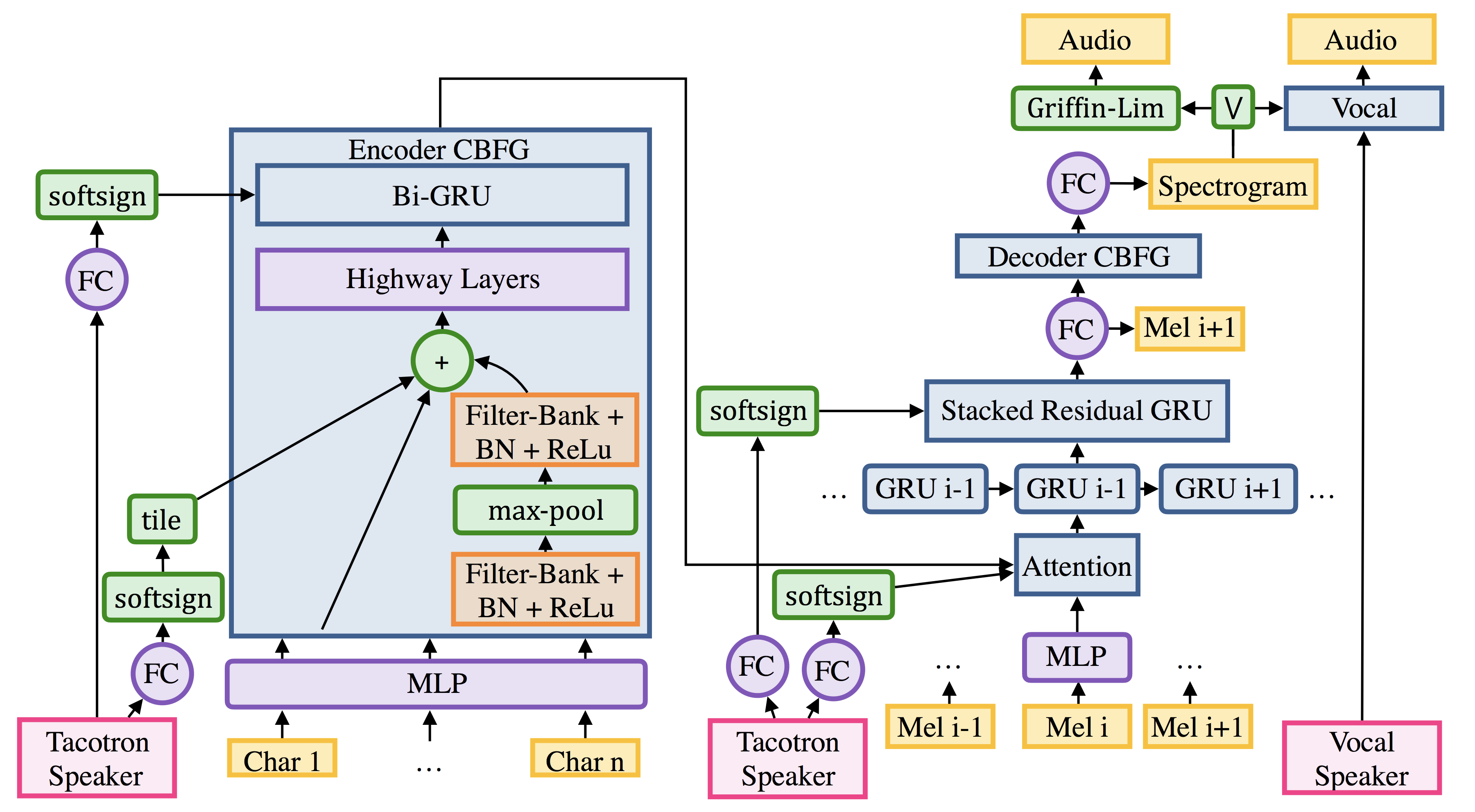
The point of using Deep Voice 2 is to train multiple speakers’ voice with one deep learning model. Tacotron model can be trained only one person’s voice and it will take N times of memory space if we want to train N number of people’s voice. But by using Deep Voice 2 model, we can train multiple speakers’ voice on a single model with smaller amount of memory space. One more advantage is that it is able to achieve high audio quality synthesis and preserve the speaker identities even with less than half an hour of data per speaker. It can be done since enough amount of data for training help to train less amount of data properly.
Data
For the datasets, the author used three public Korean figures below. I added video of each to show how they normally talk so that you can compare with the speech synthesis result.
- Sohn Suk-hee: anchor and president of JTBC broadcasting station.
- Park Geun-hye: a former President of South Korea
- Moon Jae-in: the current President of South Korea
Result
You can see and hear the speech synthesis result in this link.
15+ hours of Sohn’s data, 5+ hours of Park’s data, and 2+ hours of Moon’s data was used for training stage. In the result, every speaker is able to be identified almost perfectly, even for the Moon’s result which has only for two hours of data seems pretty valid.



