“Learning Deep Features for Discriminative Localization” proposed a method to enable the convolutional neural network to have localization ability despite being trained on image-level labels. It was presented in Conference on Computer Vision and Pattern Recognition (CVPR) 2016 by B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, and A. Torralba.
Introduction
Zhou et al. has shown that the convolutional units of various layers of convolutional neural networks actually behave as object detectors despite no supervision on the location of the object was provided. Since this ability can be lost when fully-connected layers are used for classification, fully-convolutional neural networks such as the Network in Network (NIN) and GoogLeNet have been proposed to avoid the use of fully-connected layers to minimize the number of parameters while maintaining high performance.
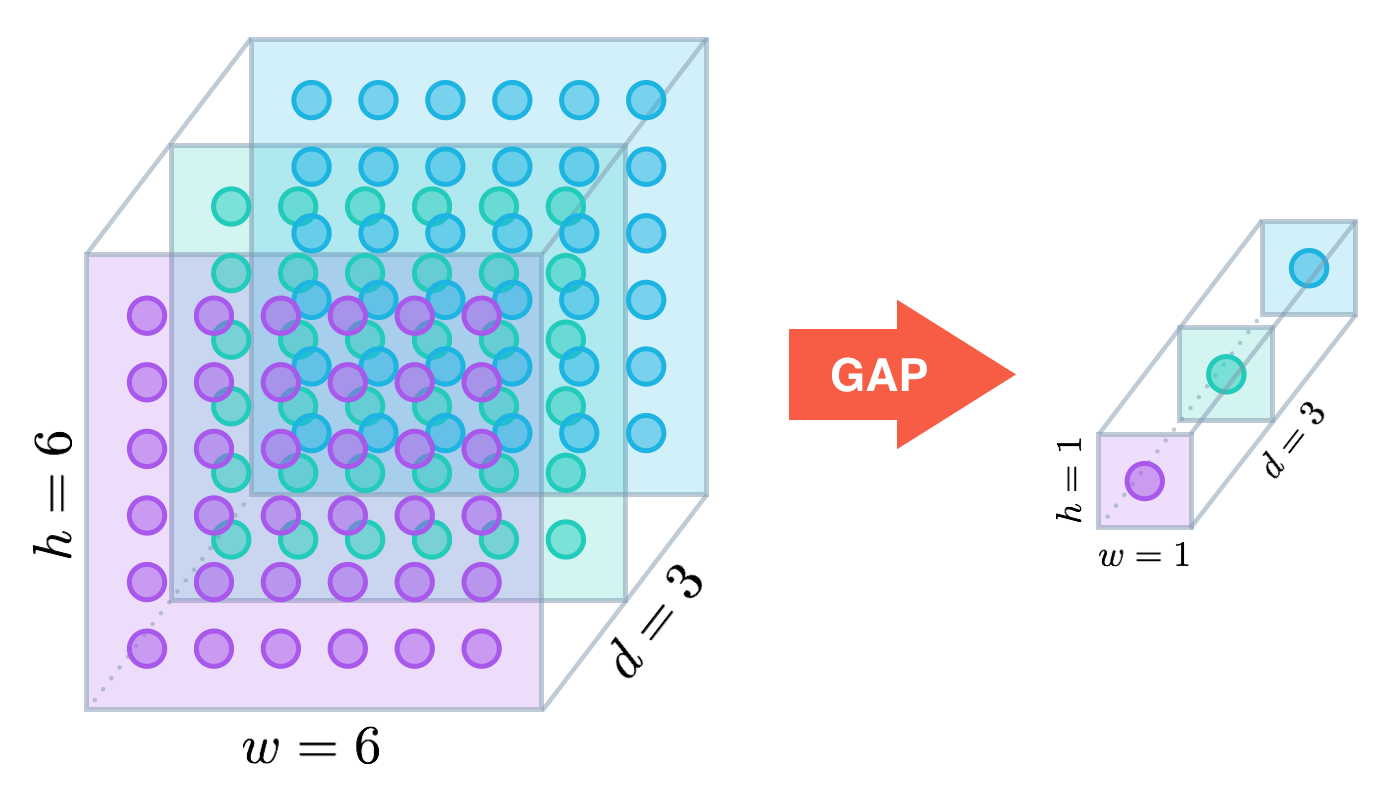
Global average pooling (GAP)
- The study Network in Network uses global average pooling which acts as a structural regularizer, preventing overfitting by reducing the total number of parameters.
- Similar to max pooling layers, GAP layers generates one feature map for each corresponding category of the classification task in the last conv layer.
(Simply, global pooling = ordinary pooling layer with pool size equals to the size of the input)
- The study proposed GAP layers designed an architecture where the final max pooling layer contained one activation map for each image category in the dataset.
- The max pooling layer was then fed to a GAP layer, which yield a vector with a single entry for each possible object in the classification task.
- And then applied a softmax activation function to yield the predicted probability of each class.
- Similar to max pooling layers, GAP layers generates one feature map for each corresponding category of the classification task in the last conv layer.
(Simply, global pooling = ordinary pooling layer with pool size equals to the size of the input)
- This paper suggests that using GAP can retain remarkable localization ability until the final layer as well.
Weakly-supervised object localization
- Oquab et al. proposed object localization with global max pooling (GMP).
- Instead of GAP, this paper proposed to use global average pooling (GAP) since the loss for average pooling benefits when the network identifies all discriminative regions for an object as compared to max pooling.
- The authors of this paper claimed that, while global average pooling is not a novel technique that this paper propose, the observation that it can be applied for accurate discriminative localization is novel.
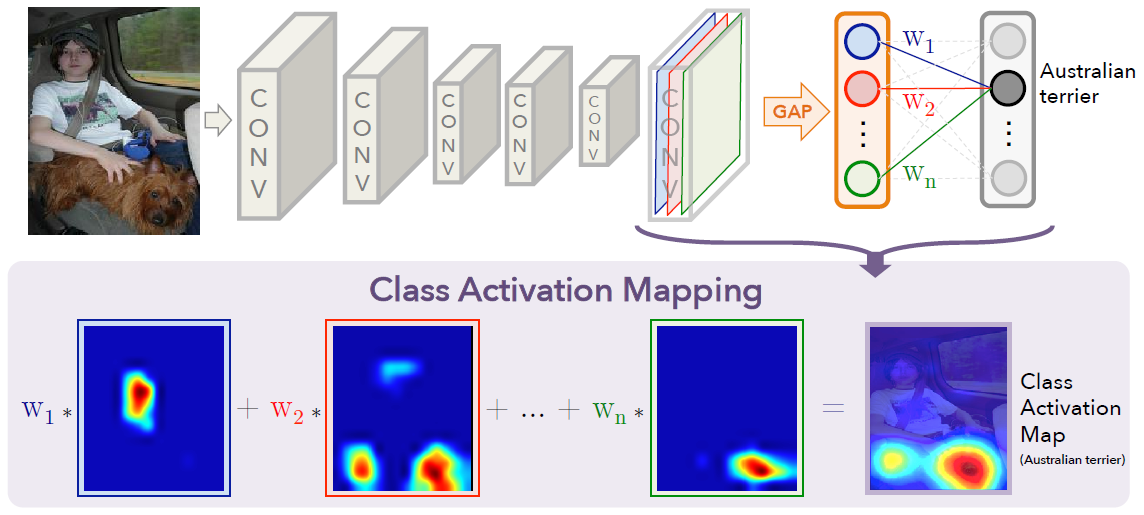
Class Activation Mapping
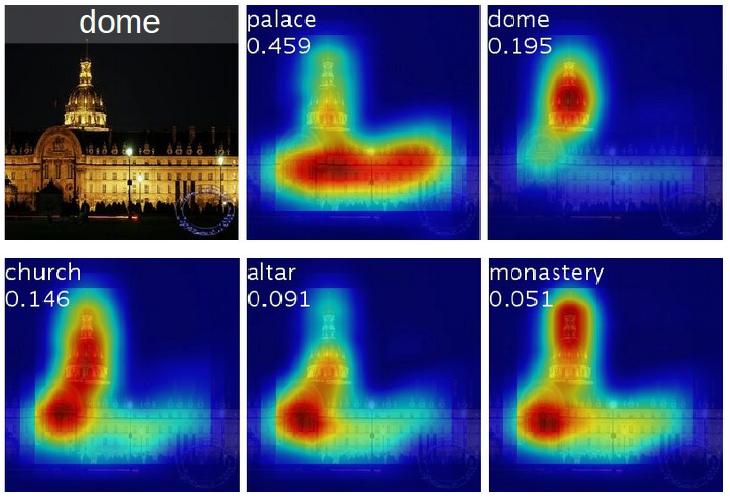
Class activation map for a category indicates the discriminative image regions used by the CNN to identify that category.
- Process of class activation mapping
- The network largely consists of convolutional layers
- Just before the final output layer (softmax in the case of categorization), it perform global average pooling on the convolutional feature maps.
- And use those as features for a fully-connected layer that produces the desired output.
- By projecting back the weights of the output layer on the convolutional feature maps, it identify the importance of the image regions (Class activation mapping).
- Below figure shows that the predicted class score is mapped back to the previous convolutional layer to generate the class activation maps (CAMs) which highlights the class-specific discriminative regions.
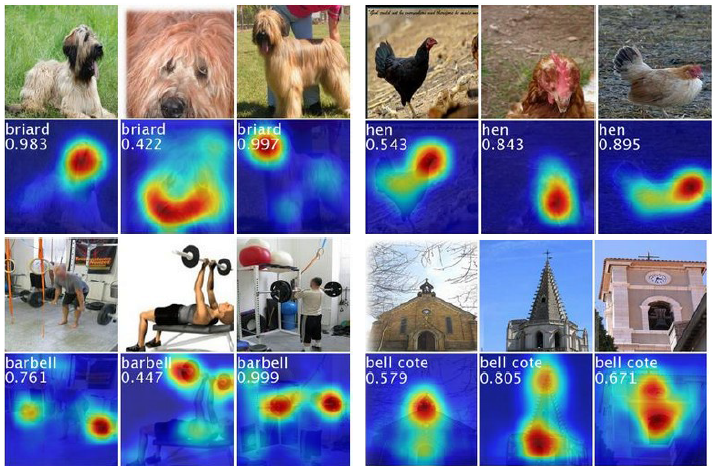
- Below figure shows some examples of the CAMs output which have discriminative regions of the images for various classes are highlighted.
- Below figure shows differences in the CAMs for a single image when using different classes to generate the maps.
- Discriminative regions for different categories are different even for a given image.
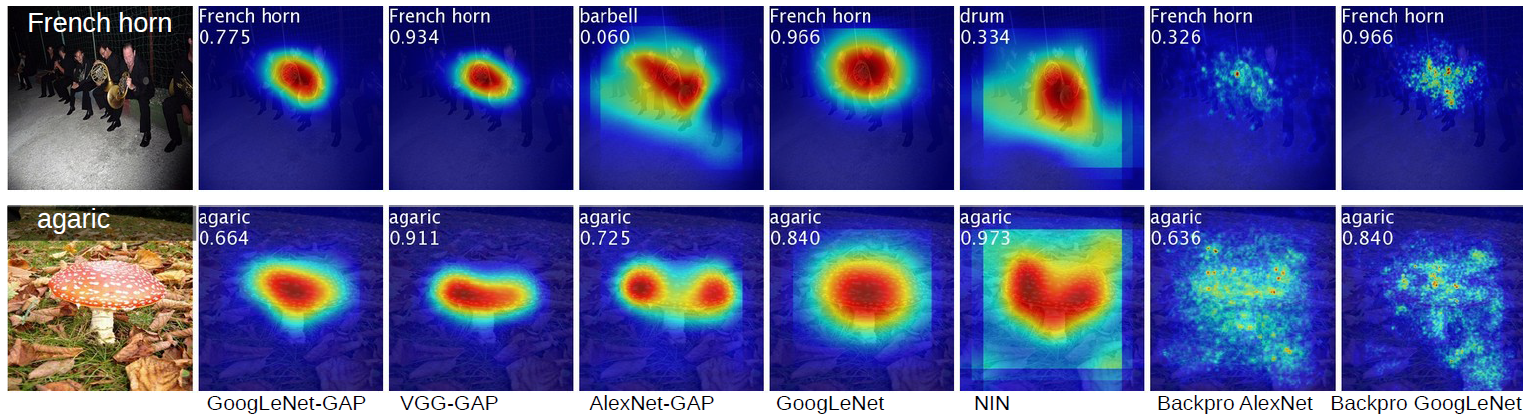
- GAP vs. GMP
- This paper claims that GAP loss encourages the network to identify the extent of the object as compared to GMP which encourages it to identify just one discriminative part.
- This is because, when doing the average of a map, the value can be maximized by finding all discriminative parts of an object as all low activations reduce the output of the particular map.
- Besides, for GMP, low scores for all image regions except the most discriminative one do not impact the score as performed a max.
- By several experiements, while GMP achieves similar classification performance as GAP, GAP outperforms GMP for localization.
Weakly-supervised Object Localization
The authors evaluated the localization ability of CAM when trained on the ILSVRC 2014 benchmark dataset.
Setup
- CNN Models
- Used popular CNNS: AlexNet, VGGnet, GoogLeNet
- Removed the fully-connected layers before the final output and replace them with GAP followed by a fully-connected softmax layer.
- Mapping resolution: the localization ability of the networks improved when the last convolutional layer before GAP had a higher spatial resolution.
- For AlexNet, the layers after conv5 (i.e., pool5 to prob) resulting in a mapping resolution of \(13 \times 13\) are removed.
- For VGGnet, the layers after conv5-3 (i.e., pool5 to prob) resulting in a mapping resolution of \(14 \times 14\) are removed.
- For GoogLeNet, the layers after inception4e (i.e., pool4 to prob) resulting in a mapping resolution of \(14 \times 14\) are removed.
- To each networks, a convolutional layer of size \(3 \times 3\), stride 1, pad 1 with 1024 units are added, followed by a GAP layer and a softmax layer.
- Each networks were fine-tuned on the images of ILSVRC.
Results
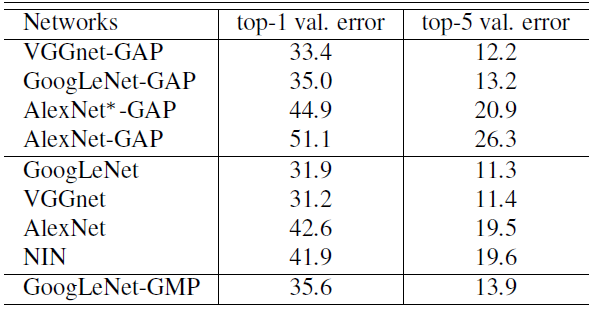
- Classification
- Below table summarizes the classification performance.
- There is a small performance drop of 1~2% when removing the additional layers from the various networks.
- It shows that GoogLeNet-GAP and GoogLeNet-GMP have similar performance on classification.
- Localization on the ILSVRC validation set
- Below table and figure are the results of localization performance on the ILSVRC validation set.
- GAP networks outperform all the baseline approaches with GoogLeNet-GAP achieving the lowest localization error.
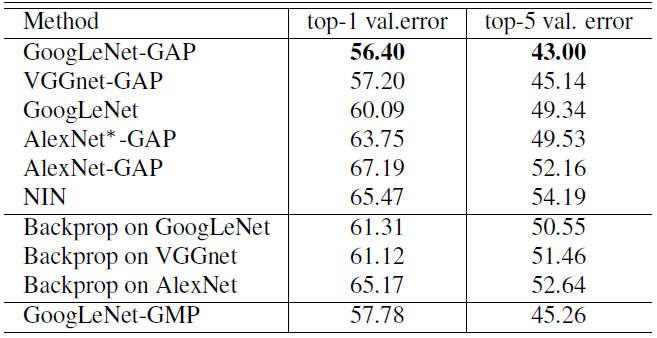
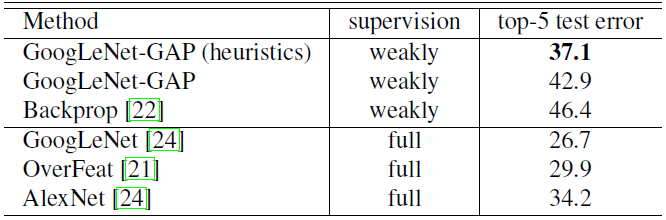
- Localization on the ILSVRC test set
- Below table and figure are the results of localization performance on the ILSVRC test set.
- GoogLeNet-GAP with heuristics achieves a top-5 error rate in a weakly-supervised setting, which is close to the top-5 error rate of AlexNet in a fully-supervised setting.