“Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning” is an advanced version of famous vision model ‘inception’ from Google. It was presented in conference on the Association for the Advancement of Artificial intelligence (AAAI) 2017 by Christian Szegedy and Sergey Ioffe and Vincent Vanhoucke and Alexander A. Alemi. (This article is still on writing…)
Residual Connection
Residual connection were introduced by He et al. for Microsoft Research team and shows advantages of utilizing additive merging of signals both for image recognition and object detection. The authors argue that residual connections are inherently necessary for training very deep convolutional models. The paper ‘inception-v4’ claim that, while it is not very difficult to train very deep networks without utilizing residual connections, the use of residual connections seems to improve the training speed greatly.
- Problem Statement
- When network depth increases, accuracy gets saturated and then degrades rapidly.
- Such degradation is not caused by overfitting, and adding more layers to a suitably deep model leads to higher training error.
- Proposed Solution: Residual Connection
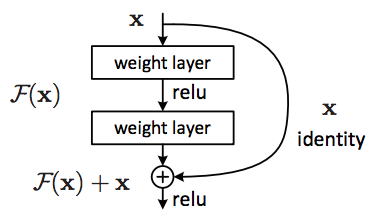
- Instead of hoping each stack of layers directly fits a desired underlying mapping, we explicitly let these layers fit a residual mapping.
- The original mapping is recast into \(F(x) + x\).
- We hypothesize that it is easier to optimize the residual mapping than to optimize the original, unreferenced mapping.
- To the extreme, if an identity were optimal, it would be easier to push the residual to zero than to fit an identity mapping by a stack of nonlinear layers.
- Why Residual Connection Works?
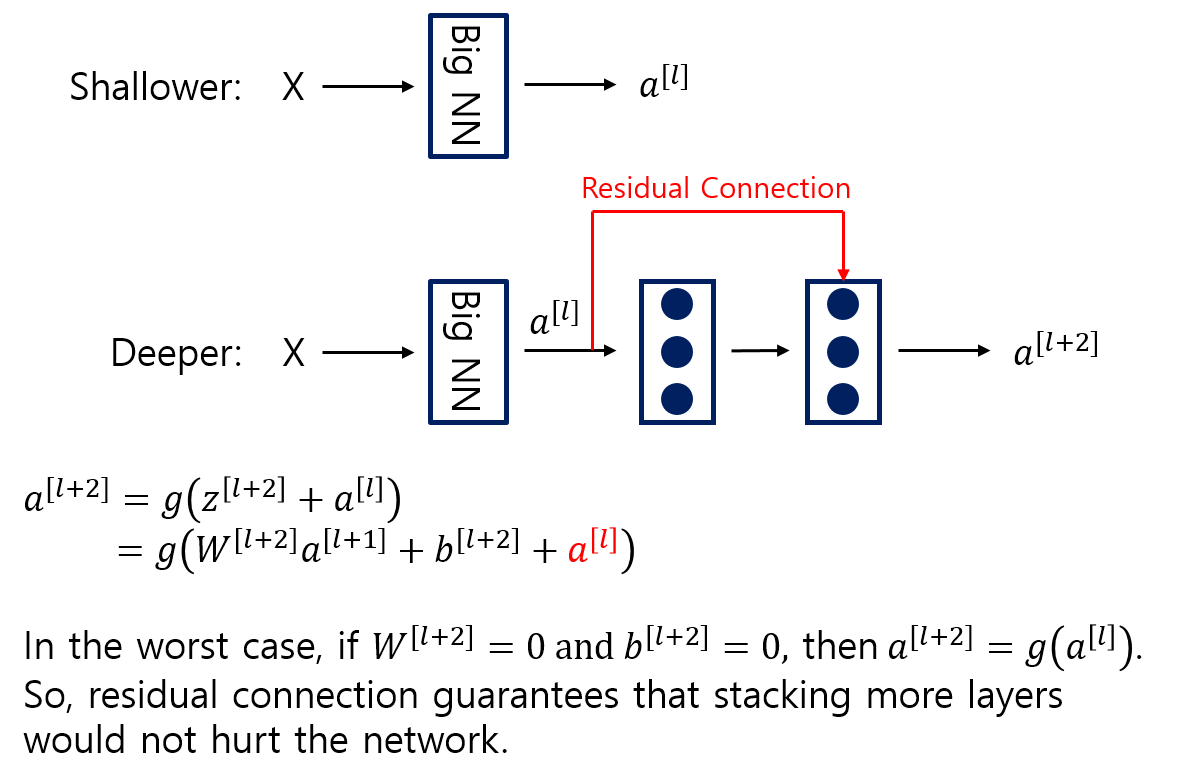
- Let us consider a shallower architecture and its deeper counterpart that adds more layers onto it.
- There exists a solution to the deeper model by construction: the layers are copied from the learned shallower model, and the added layers are identity mapping.
- The existence of this constructed solution indicates that a deeper model should produce no higher training error than its shallower counterpart.
History of Inception
- GoogLeNet or Inception-v1
- Inception-v2
- Refined by the introduction of batch normalization
- Inception-v3
- Improved by additional factorization ideas in the third iteration



