“Extreme clicking for efficient object annotation” proposes a better way to annotate object bounding boxes with four clicks on the object. It is a further research of “Training object class detectors with click supervision” which proposes efficient way of annotating bounding boxes with one or two click supervision. This paper was presented in the International Conference on Computer Vision (ICCV) 2017 by Jasper R. R. Uijlings and Vittorio Ferrari (Google AI Perception).
Summary
- Problem Statement
- Manually annotating object bounding boxes is important but very time consuming.
- Clicking on imaginary corners of a tight box around the object is difficult as these corners are often outside the actual object and several adjustments are required.
- Research Objective
- To minimize human annotation effort while producing high-quality detectors.
- Proposed Solution
- Extreme clicking: annotator clicks on four physical points on the object (top, bottom, left-, right-most points)
- Contribution
- Annotation time is only 7s per box, 5\(\times\) faster than the traditional way of drawing boxes.
- The quality of the boxes is as good as the original ground-truth.
- Detectors trained on our annotations are as accurate as those trained on the original ground-truth.
- This paper shows how to incorporate them into GrabCut to obtain more accurate segmentations
- Semantic segmentations models trained on these segmentations outperform those trained on segmentations derived from bounding boxes.
Introduction
This paper proposes new scheme called extreme clicking: annotator clicks on four extreme points of the object.
 Figure 1: Annotating an instance of motorbike: (a) The conventional way of drawing a bounding box. (b) Proposed extreme clicking scheme
Figure 1: Annotating an instance of motorbike: (a) The conventional way of drawing a bounding box. (b) Proposed extreme clicking scheme
- Advantage of extreme clicking
- Extreme points are not imaginary, but are well-defined physical points on the object
- No rectangle is involved, neither real nor imaginary
- Only a single task is performed by the annotator thus avoiding task switching
- No separate box adjustment step is required
- No “submit” button is necessary (it terminates after four clicks)
Object Segmentation from Extreme Clicks
Extreme clicking results not only in high-quality bounding box annotations, but also in four accurate object boundary points.
- Thinking of segmenting an object instance in image \(I\) as a pixel labeling problem
- Each pixel \(p \in I\) should be labeled as either object (\(l_p = 1\)) or background ($$l_p = 0)
- A labeling \(L\) of all pixels represents the segmented object
- Employ a binary pairwise energy function \(E\) defined over the pixels and their labels
- \(U\): unary potential that evaluates how likely a pixel \(p\) is to take label \(l_p\) according to the object and background appearance models
- \(V\): encourages smoothness by penalizing neighboring pixels taking different labels
Initial Object Surface Estimate
For GrabCut to work well, it is important to have a good initial estimate of the object surface to initialize the appearance model and to clamp certain pixels to object.
- Finding the path connecting each pair of consecutive extreme clicks which is most likely to belong to the object boundary
- For this, apply a strong edge detector to obtain a boundary probability \(e_p \in [0,1]\) for every pixel \(p\) (second row in Fig. 2)
- Define the best boundry path between two consecutive extreme clicks as the shortest path whose minimum edge-response is the highest (magenta in Fig. 2)
- Minimize \(\sum _p (1-e_p)\) for pixels \(p\) on the path
- The resulting object boundary paths yield an initial estimate of the object outlines
- Use the surface within the boundary estimates to initialize the object appearance model used for \(U\) (green in Fig. 2)
- From the surface, obtain a skeleton using standard morphology (dark green in Fig. 2)
- This skeleton is very likely to be object, so we clamp its pixel-labels to be object (\(l_s=1\) for all pixels \(s\) on the skeleton)
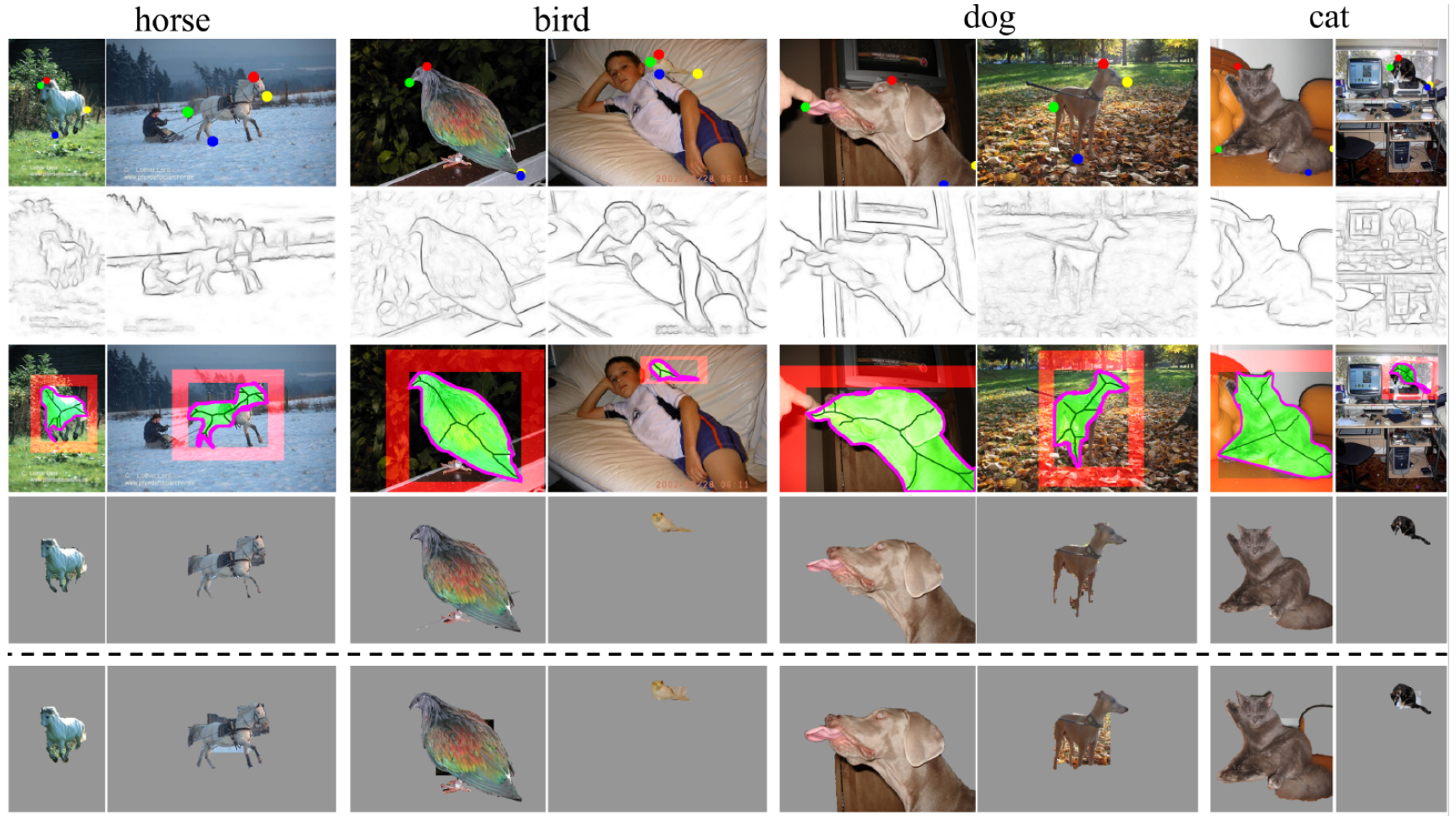
Figure 2: Visualization of input cues and output of GrabCut.
- In Figure 2:
- First row: input with annotator’s extreme clicks
- Second row: output of edge detector
- Third row: inputs for GrabCut, the pixels used to create background appearance model(red), object appearance model (bright green), initial boundary estimate (magenta), skeleton pixels which we clamp to have the object label (dark green)
- Fourth row: output of GrabCut when using new inputs
- Last row: output when using only a bounding box
Appearance Model
- Appearance model consists of two GMMs as in classic GrabCut
- One for the object (\(l_p=1\)) and one for the background (\(l_p=0\))
- Each GMM has five components, where each is a full-covariance Gaussian over the RGB color space
- Segment the object within the bounding box, intuitively only the immediate background is relevant, not the whole image.
- Use a small ring around the bounding box for initializing the backgorund model
- The background model is initialized from the immediate background and the object model is initialized from all pixels within the box
- By using extreme clicks, we obtain an initial object surface estimate from which we initialize the object appearance model.
Clamping Pixels
- GrabCut decides to label all pixels either as object or background
- It clamps center area of the bounding box as object, but it maight not an object if it is not convex
- In this paper, we estimate the pixels to be clamped by skeletonizing the object surface estimate derived from our extreme clicks.
Pairwise Potential \(V\)
- \(\sum _{p,q} V(l_p,l_q)\) on the equation (1) is used as penalty depends on the RGB difference between pixels.
- In this paper, we instead use the sum of the edge responses of the two pixels given by the edge detector.
Experiments
Dataset
- Implement annotation scheme on Amazon Mechanical Turk (AMT) and collect extreme click annotations
- the trainval set of PASCAL VOC 2007 (5011 images)
- the training set of PASCAL VOC 2012 (5712 images)
- Contain 20 object categories
- For every image, we annotate a single instance per class
Result

Table 1: Comparison of extreme clicking and PASCAL VOC ground-truth.

Table 2: Comparison of extreme clicking and alternative fast annotation approaches.
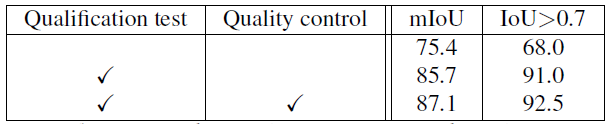 Table 3: Influence of the qualification test and quality control on the accuracy of extreme click annotations (on 200 images from PASCAL VOC 2007).
Table 3: Influence of the qualification test and quality control on the accuracy of extreme click annotations (on 200 images from PASCAL VOC 2007).
 Table 4: Segmentation performance on the val set of PASCAL VOC 2012 dataset using different types of annotations.
Table 4: Segmentation performance on the val set of PASCAL VOC 2012 dataset using different types of annotations.
References
- Paper: Extreme clicking for efficient object annotation, ICCV2017
- Supplementary material: Extreme clicking for efficient object annotation
- Reference paper: “GrabCut” — Interactive Foreground Extraction using Iterated Graph Cuts, SIGGRAPH2004
- Reference paper: Structured forests for fast edge detection, ICCV2013



