“Deep image retrieval: learning global representations for image search” proposes an approach for instance-level image retrieval. It was presented in the ECCV2016 by Albert Gordo, Jon Almazan, Jerome Revaud, and Diane Larlus from Computer Vision Group, Xerox Research Center Europe.
Summary
- Problem Statement
- Recent works leveraging deep architectures for image retrieval are mostly limited to using a pre-trained network as local feature extractor.
- Research Objective
- To leverages a deep architecture trained for the specific task of image retrieval
- Proposed Solution
- Propose an approach for instance-level image retrieval, which produces a global and compact fixed-length representation for each image by aggregating many region-wise descriptors.
- The proposed architecture produces a global image representation in a single forward pass.
- The paper shows that using clean training data is key to the success of our approach.
- To that aim, the paper uses a large scale but noisy landmark dataset and develop an automatic cleaning approach.
- Propose an approach for instance-level image retrieval, which produces a global and compact fixed-length representation for each image by aggregating many region-wise descriptors.
- Contribution
- Use a three-stream Siamese network that explicitly optimizes the weights of the R-MAC representation for the image retrieval task by using a triplet ranking loss.
- Employ a region proposal network to learn which regions should be pooled to form the final global descriptor.
- The proposed approach outperforms previous approaches based on global descriptors, costly local descriptor indexing and spatial verification.
Related Works
Conventional Image Retrieval
- Encoding techniques, such as the Fisher Vector, or VLAD, combined with compression produce global descriptors that scale to larger databases at the cost of reduced accuracy.
- All these methods can be combined with other post-processing techniques such as query expansion.
CNN-based Retrieval
- Although CNN-based retrieval outperform other standard global descriptors, their performance is significantly below the state of the art.
- Several improvements were proposed to overcome their lack of robustness to scaling, cropping and image clutter.
- R-MAC is an approach that produces a global image representation by aggregating the activation features of a CNN in a fixed layout of spatial regions.
- The result is a fixed-length vector representation that, when combined with re-ranking and query expansion, achieves results close to the state of the art.
Fine-tuning for Retrieval
- In this paper, the authors confirm that fine-tuning the pre-trained models for the retrieval task is indeed crucial, but argue that one should use a good image representation (R-MAC) and a ranking loss instead of a classification loss.
Method
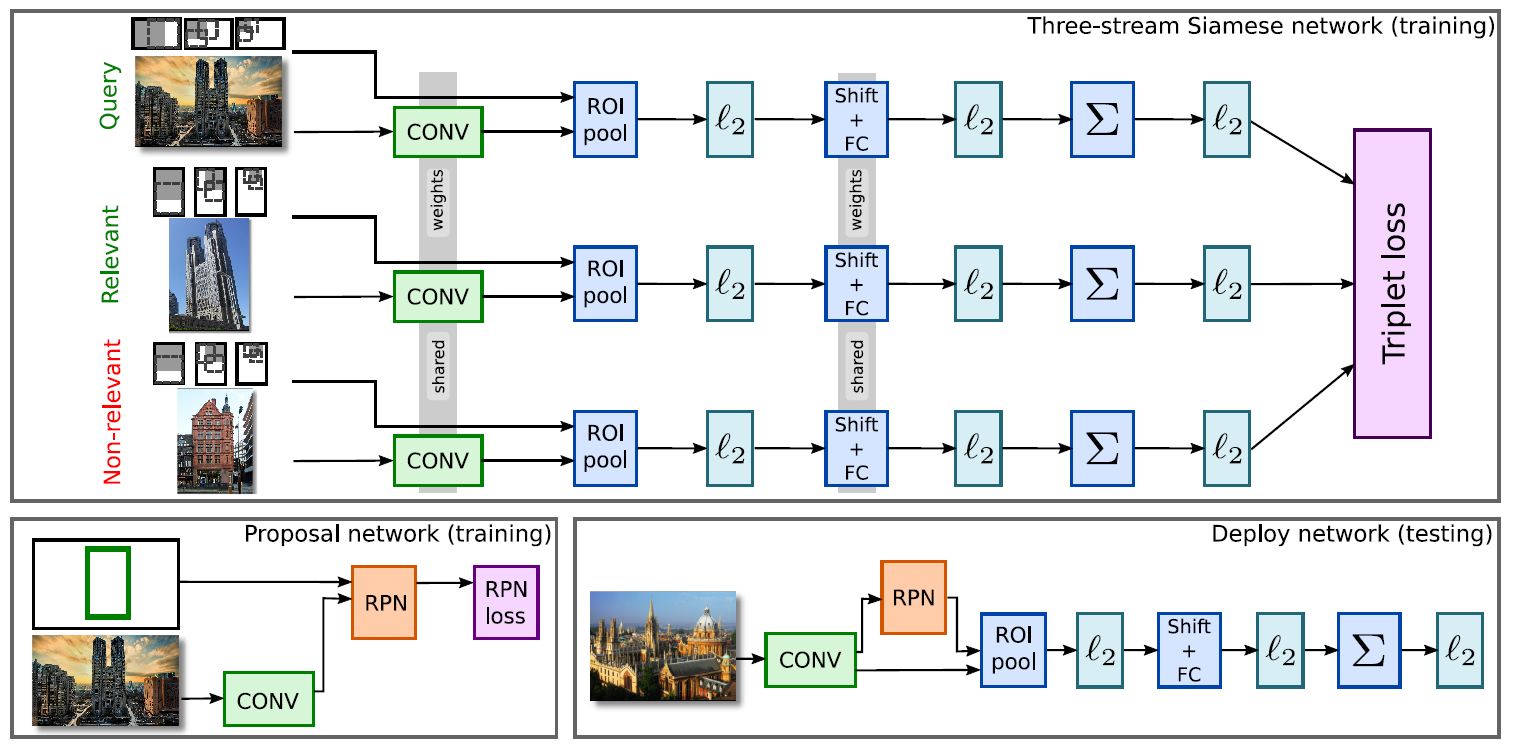
Figure 1: Summary of the proposed CNN-based representation tailored for retrieval. At training time, image triplets are sampled and simultaneously considered by a triplet-loss that is well-suited for the task (top). A region proposal network (RPN) learns which image regions should be pooled (bottom left). At test time (bottom right), the query image is fed to the learned architecture to effciently produce a compact global image representation that can be compared with the dataset image representations with a simple dot-product.
Learning to Retrieve Particular Objects
R-MAC revisited
- R-MAC is a global image representation particularly well-suited for image retrieval.
- The R-MAC extraction process is summarized in any of the three streams of the networks in Fig. 1.
- The convolutional layers extract activation features (local features) that do not depend on the image size of its aspect ratio.
- Local features are max-pooled in different regions of the image using a multi-scale rigid grid with overlapping cells.
- These pooled region features are l2-normalized, whitened with PCA and l2-normalized again.
- Comparing two image vectors with dot-product can then be interpreted as an approximate many-to-many region matching.
- All these operations are differentiable.
- The spatial pooling in different regions is equivalent to the Region of Interest (ROI) pooling.
- The PCA projection can be implemented with a shifting and a fully connected (FC) layer.
- One can implement a network to produce the final R-MAC representation in a single forward pass.
Learning for Particular Instances
- This paper proposes a ranking loss based on image triplets.
- It explicitly enforces that, given a query, a relevant element to the query and a non-relevant one, the relevant one is closer to the query than the other one.
- To do so, the authors use three-stream Siamese network in Fig. 1.
- Let \(I_q\) be a query image with R-MAC descriptor \(q\), \(I^+\) be a relevant image with descriptor \(d+\), and \(I^-\) be a non-relevant image with descriptor \(d^-\), and \(m\) is a scalar that controls the margin. The ranking triplet loss is defined as,
Proposal Pooling
- The rigid grid used in R-MAC to pool regions tries to ensure that the object of interest is covered by at least one of the regions and it has two problems
- As the grid is independent of the image content, it is unlikely that any of the grid regions accurately align with the object of interest.
- Many of the regions only cover background.
- This paper proposes to replace the rigid grid with region proposals produced by Region Proposal Network (RPN) trained to localize regions of interest in images.
- It is consists of a fully-convolutional network built on top of the convolutional layers of R-MAC.
Leveraging Large-scale Noisy Data
- In order to clean the dataset, the authors run a strong image matching baseline within images of each landmark class
- They use SIFT and Hessian-Affine keypoint detectors and match keypoints using the first-to-second neighbor ratio rule.
Experiments
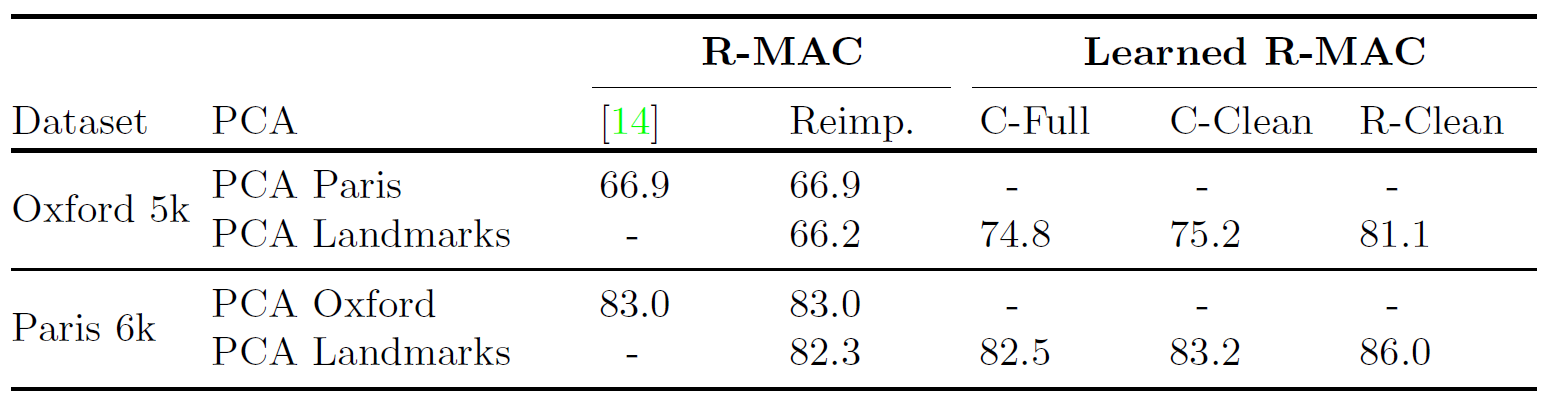
Figure 2: Comparison of R-MAC, our reimplementation of it and the learned versions fine-tuned for classification on the full and the clean sets (C-Full and C-Clean) and fine-tuned for ranking on the clean set (R-Clean). All these results use the initial regular grid with no RPN.
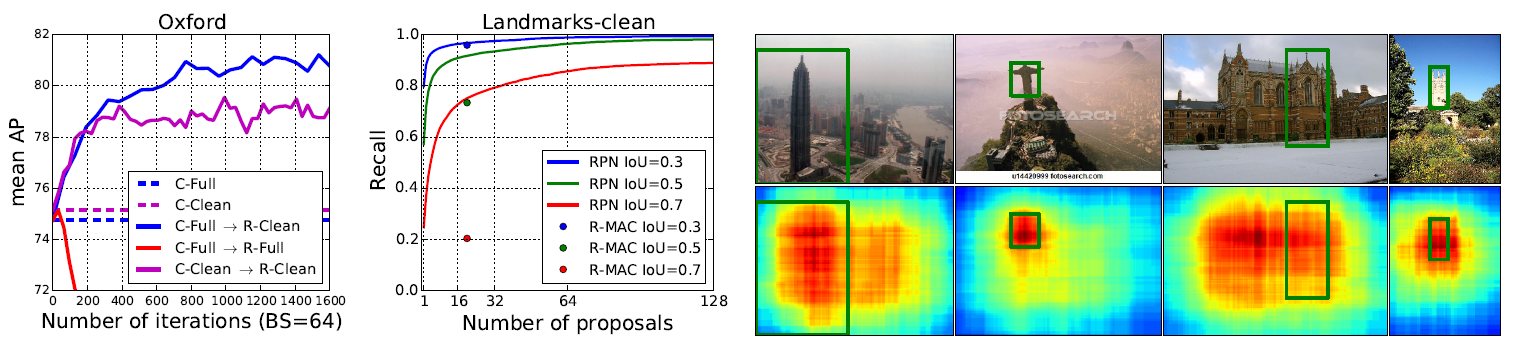
Figure 3: Left: evolution of mAP when learning with a rank-loss for diffierent initializations and training sets. Middle: landmark detection recall of our learned RPN for several IoU thresholds compared to the R-MAC fixed grid. Right: heat-map of the coverage achieved by our proposals on images from the Landmark and the Oxford 5k datasets. Green rectangles are ground-truth bounding boxes.
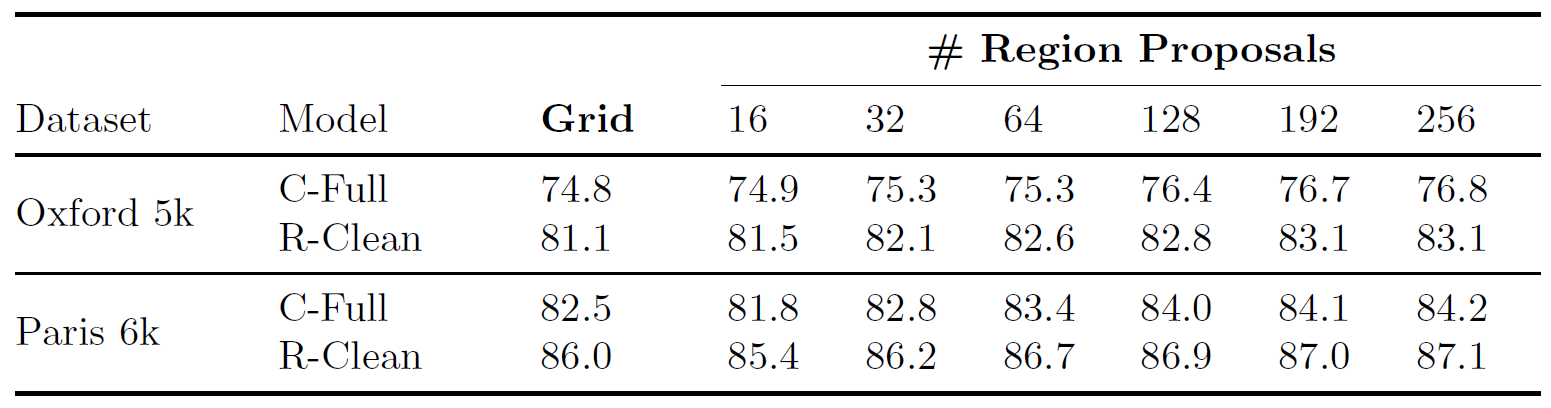
Figure 4: Proposals network. mAP results for Oxford 5k and Paris 6k obtained with a fixed-grid R-MAC, and our proposal network, for an increasingly large number of proposals, before and after fine-tuning with a ranking-loss. The rigid grid extracts, on average, 20 regions per image.
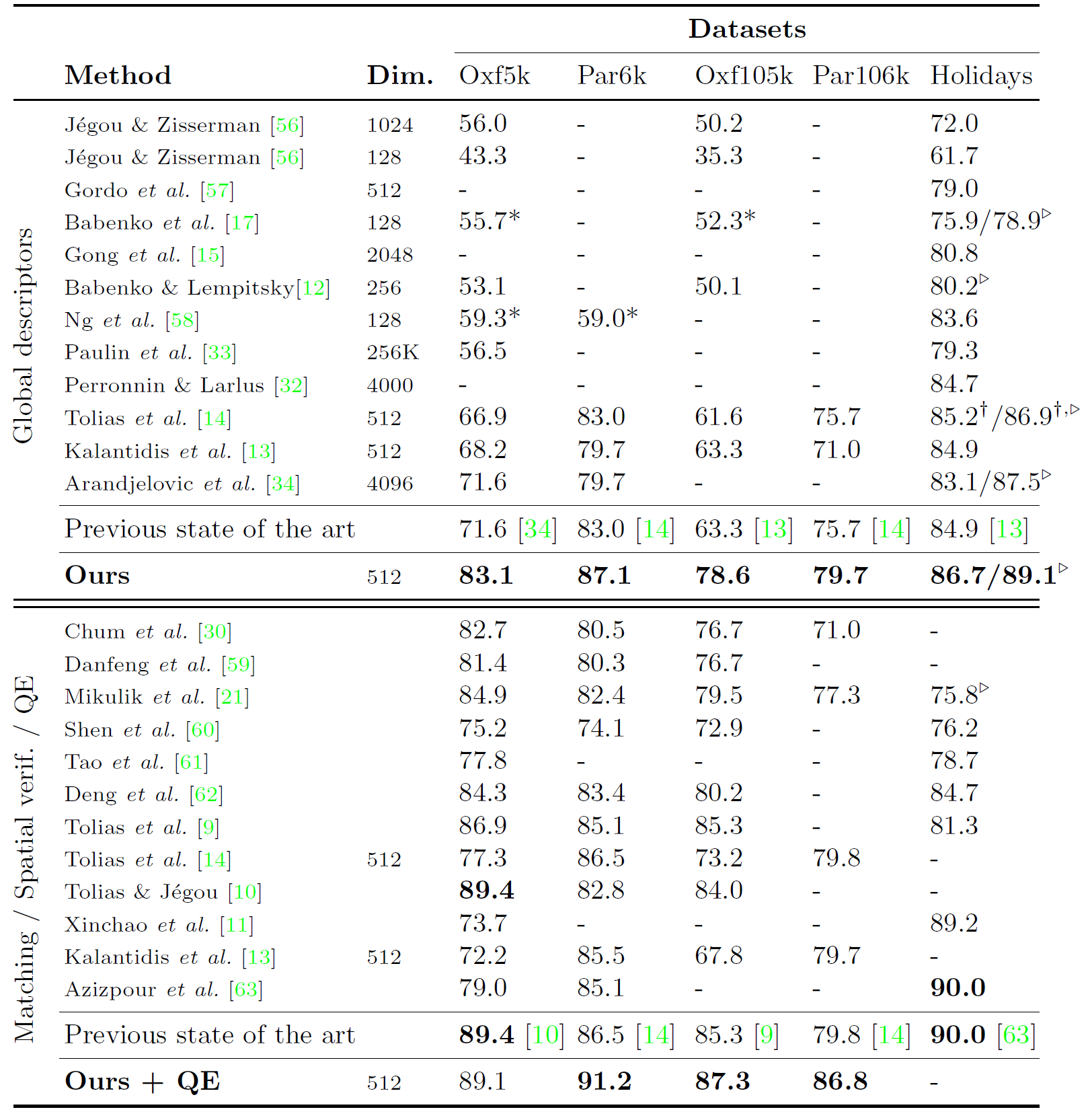
Figure 5: Accuracy comparison with the state of the art. Methods marked with an * use the full image as a query in Oxford and Paris instead of using the annotated region of interest as is standard practice. Methods with a ▷ manually rotate Holidays images to fix their orientation. † denotes our reimplementation. We do not report QE results on Holidays as it is not a standard practice.



