“Training object class detectors with click supervision” proposes efficient way of annotating bounding boxes for object class detectors. It was presented in the Conference on Computer Vision and Pattern Recognition (CVPR) 2017 by Jasper R. R. Uijlings and Vittorio Ferrari (Google AI Perception).
Summary
- Problem Statement
- Manually drawing bounding boxes for training object class detectors is time consuming.
- Even though object detectors can be trained under weak supervision, the resulting detectors deliver lower accuracy.
- Research Objective
- To minimize human annotation effort while producing high-quality detectors.
- Proposed Solution
- Propose annotating objects by clicking on their centers
- Incorporate those clicks into existing Multiple Instance Learning techniques for weakly supervised object localization
- Contribution
- Delivers high-quality detectors, performing substantially better than those produced by weakly supervised techniques, with a modest extra annotation effort
- Perform in a range close to those trained from manually drawn bounding boxes
- Reduces total annotation time by 9\(\times\) to 18\(\times\).
Introduction
Typically, object detectors are trained under full supervision, which requires manually drawing tight object bounding boxes. However, manually drawing tight object bounding boxes takes lots of time.
- Full supervision: learning with full object bounding boxes
Object detectors can also be trained under weak supervision using only image-level labels. This is cheaper but the resulting detectors typically deliver only about half the accuracy of their fully supervised counterparts.
- Weak supervision: learning with only image-level labels without object bounding boxes
Workflow of Collecting Click Annotation
- Center-click annotation: Annotators click on the center of an imaginary bounding box enclosing the object.
- Asked two different annotators to get more accurate estimation
- Given the two clicks, the size of the object can be estimated, by exploiting a correlation between the object size and the distance of the click to the true center (error).
- Incorporate these clicks into a reference Multiple Instance Learning (MIL) framework which was originally designed for weakly supervised object detection.
- It jointly localizes object bounding boxes over all training images of an object class.
- It iteratively alternates between retraining the detector and re-localizing objects.
- We use the center-clicks in the re-localization phase.
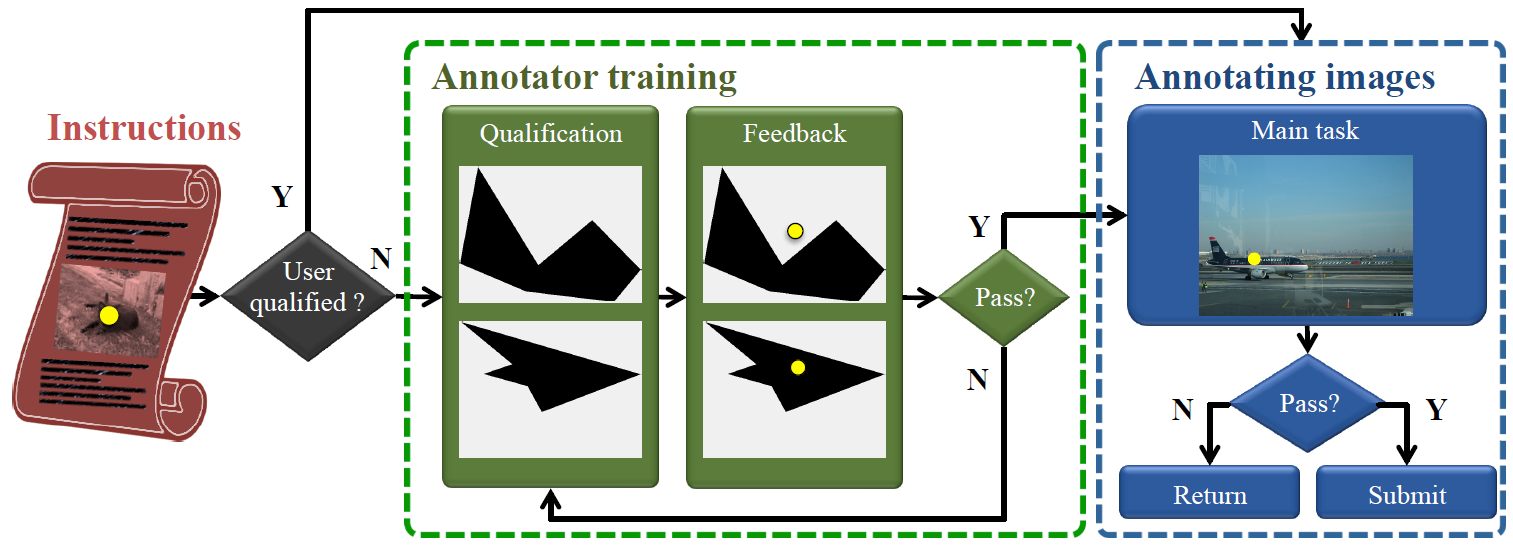 Figure 1: The workflow of crowd-sourcing framework for collecting click annotations.
Figure 1: The workflow of crowd-sourcing framework for collecting click annotations.
Click Supervision
Click annotation schemes have been used
- Part-based detection to annotate part locations of an object
- in human pose estimation
- in reducing the annotation time for semantic segmentation
Incorporating clicks into WSOL
Incorporating click supervision into a reference Multiple Instance Learning (MIL) framework, which is typically used in WSOL.
Reference Multiple Instance Learning (MIL)
- Training set contains
- Positive images which contain the target class
- Negative images which do not contain the target class
- Represent each image as a bag of object proposals extracted using Edge-Boxes.
- Describe each object proposals with a 4096-dimensional feature vector using the Caffe implementation of the AlexNet CNN.
- Pretrained the CNN on the ILSVRC dataset using only image-level labels (no bounding box annotations)
- In order to find the true positive proposals from which to learn an appearance model for the object class,
the authors iteratively build an SVM appearance model \(A\) by alternating between two steps:
- Step 1. re-localization: in each positive image, select the proposal with the highest score given by the current appearance model \(A\).
- Step 2. re-training: re-train the SVM using the current selection of proposals from the positive images, and all proposals from negative images.
Refinements
- In order to obtain a competitive baseline, the authors apply two refinements to the standard MIL framework.
- Use multi-folding, which helps escaping local optima
- Combine the score given by the appearance model \(A\) with a general measure of “objectness” \(O\)
- At step 1, the authors linearly combine the scores \(A\) and \(O\) under the assumption of equal weights.
Deep MIL
- After MIL converges, the author perform two additional iterations where during the step 2.
- The authors deeply re-train the whole CNN network, instead of just an SVM on top of a fixed feature representation.
- Use Fast R-CNN as the appearance model \(A\)
One-click Supervision
Box Center Score \(S_{bc}\)
 Figure 2: Box center score \(S_{bc}\), (left): One-click annotation. (middel): Two-click annotation on the same instance.
(right): Two-click annotation on different instances.
Figure 2: Box center score \(S_{bc}\), (left): One-click annotation. (middel): Two-click annotation on the same instance.
(right): Two-click annotation on different instances.
- A score function \(S_{bc}\), which represents the likelihood of a proposal \(p\) covering the object according to its center point \(c_p\) and the click \(c\)
- \(\parallel c_p - c \parallel\): Euclidean distance in pixels between \(c\) and \(c_p\).
- \(\sigma _{bc}\): controls how quickly the \(S_{bc}\) decreases as \(c_p\) gets farther from \(c\).
Use in Re-localization
The authors use the box center cue \(S_{bc}\) in the re-localization step of MIL to get better appearance models in the next re-training iteration.
\[S_{ap}(p) \cdot S_{bc}(p;c,\sigma _{bc})\]Use in Initialization
Instead of initializing the positive training samples from the complete images, the authors construct windows centered on the click while at the same time having maximum size without exceeding the image borders.
Two-click Supervision
Two-click supervision helps use to estimate the object center even more accurately. Moreover, we can estimate the object area based on the distance between the two clicks.
Box Center Score \(S_{bc}\)
By averaging the positions of two clicks we can estimate the object center more accurately.
\[c = \frac{(c_1 + c_2)}{2} \\ S_{bc}(p; c, \sigma _{bc}) = e^{-\frac{\parallel c_p - c \parallel ^2}{2\sigma ^2 _{bc}}}\]Box Area Score \(S_bc\)
As errors made by two annotators are independent, the distance between their two clicks increases as the object area increases (on average). Therefore we estimate the object area based on the distance between the two clicks.
- \(\mu(\parallel c_1 - c_2 \parallel)\): a function that estimates the logarithm of the object area
- For each proposal \(p\), a box area score \(S_{ba}\) that represents the likelihood of \(p\) covering the object according to the ratio between the proposal area and the estimated object area:
Use in re-localization
Use all cues in the final score function for a proposal \(p\) during the re-localization step of MIL:
\[S(p) = S_{ap}(p)\cdot S_{bc}(p;c_1,c_2,\sigma _{bc}) \cdot S_{ba}(p;c_1,c_2,\sigma_{ba})\]Experimental Results
 Figure 3: Examples of objects localized on the trainval set of PASCAL VOC 2007 using one-click (blue), two-click (green) and the reference MIL (red)
Figure 3: Examples of objects localized on the trainval set of PASCAL VOC 2007 using one-click (blue), two-click (green) and the reference MIL (red)
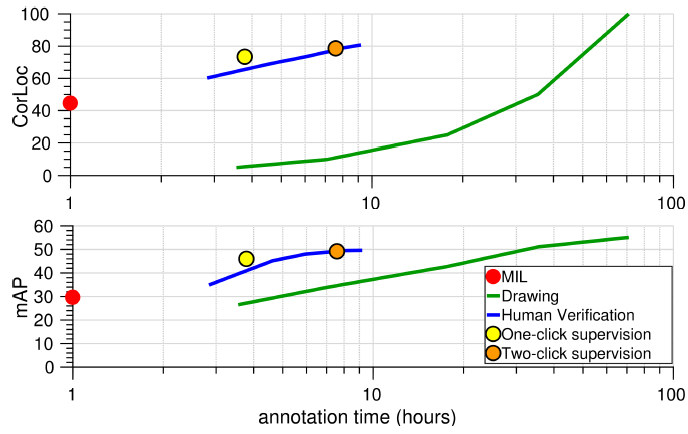 Figure 4: Evaluation on PASCAL VOC 2007.
Correct Localization (CorLoc) and mean average precision (mAP) performance against human annotation time in hours(log-scale)
Figure 4: Evaluation on PASCAL VOC 2007.
Correct Localization (CorLoc) and mean average precision (mAP) performance against human annotation time in hours(log-scale)
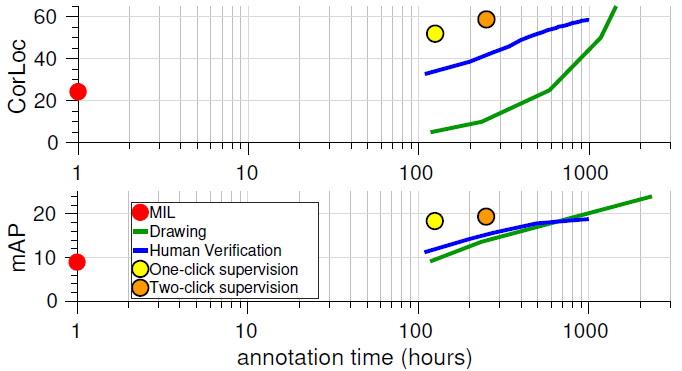 Figure 5: Evaluation on MSCOCO.
CorLoc and mAP performance against human annotation time in hours(log-scale)
Figure 5: Evaluation on MSCOCO.
CorLoc and mAP performance against human annotation time in hours(log-scale)



