“Network In Network” is one of the most important study related convoutional neural network because of the concept of 1 by 1 convolution and global average pooling. It was presented in International Conference on Learning Representations (ICLR) 2014 by Min Lin, Qiang Chen, and Shuicheng Yan.
Summary
- Problem of structure of traditional CNN
- The convolution filter in CNN is a generalized linear model (GLM) for the underlying data patch.
- The level of abstraction is low with GLM.
- Proposed Solution: Network In Network
- In NIN, the GLM is replaced with a micro network structure which is a general nonlinear function approximator.
- The feature maps are obtained by sliding the MLP over the input in a similar manner as CNN and are then fed into the next layer.
- The overall structure of the NIN is the stacking of multiple mlpconv layers.
- Problem of fully-connected layers in traditional CNN
- Difficult to interpret how the category level information from the objective cost layer is passed back to the previous convolution layer
- Prone to overfitting and heavily depend on dropout regularization
- Proposd Solution: Global Average Pooling
- More meaningful and interpretable as it enforces correspondance between feature maps and categories
- Work as structural regularizer, which natively prevents overfitting for the overall structure
Convolutional Neural Networks
Classic convolutional neuron networks consist of alternatively stacked convolutional layers and spatial pooling layers. The convolutional layers generate feature maps by linear convolutional filters followed by nonlinear activation functions.
Using the linear rectifier as an example, the feature map can be calculated as follows:
\[f_{i,j,k} = max(w^T_k x_{i,j}, 0)\]\((i,j)\) is the pixel index in the feature map, \(x_{ij}\) stands for the input patch centered at location \((i,j)\), and \(k\) is used to index the channels of the feature map.
In conventional CNN, linear convolution is not enough for abstraction and representations that achieve good abstraction are generally highly non-linear functions of the input data. So, NIN is proposed that the micro network is integrated into CNN structure in persuit of better abstractions for all levels of features.
Network In Network
MLP Convolution Layers
This paper suggests new type of layer called mlpconv, in which MLP replaces the GLM to convolve over the input. The reason to choose multilayer perceptron is
- It is compatible with the structure of convolutional neural networks, which is trained using back-propagation.
- It can e a deep model itself, which is consistent with the spirit of feature re-use.
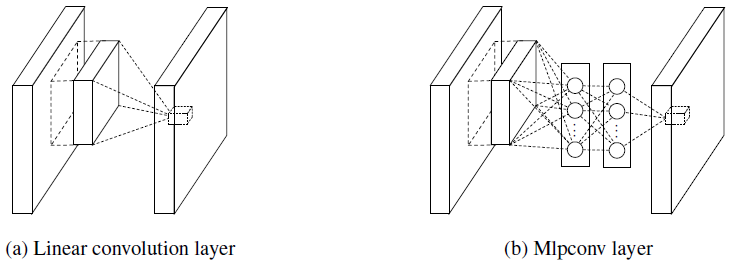 Figure 1: Comparison of linear convolution layer and mlpconv layer.
Figure 1: Comparison of linear convolution layer and mlpconv layer.
When \(n\) is the number of layers in the multilayer perceptron, mlpconv layer can be calculated as follows:
\[f_{i,j,{k_1}}^1 = max({w^1_{k_1}}^T x_{i,j}+b_{k_1}, 0) \\ ... \\ f_{i,j,{k_n}}^n = max({w^n_{k_n}}^T f_{i,j}^{n-1}+b_{k_n}, 0)\]1x1 Convolution
Mlpconv can be explained by a convolution layer with 1x1 convolution kernel. What the 1x1 convolution kernel does is:
- It leads to dimension reductionality for the number of channel (e.g. an image of 100x100 with 30 features on convolution with 20 filters of 1x1 would result in size of 100x100x20.)
- Comparison with pooling layer which reduce the height and width of the feature
- It helps by adding non-linearity to the network in order to learn higher abstraction.
- 1x1 filter calculate a linear combination of all corresponding pixels (neurons) of the input channels and output the result through an activation function which adds up the non-linearity.
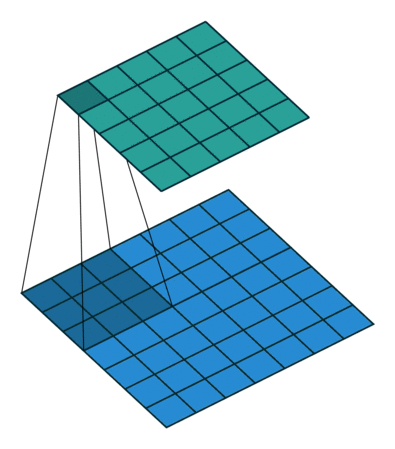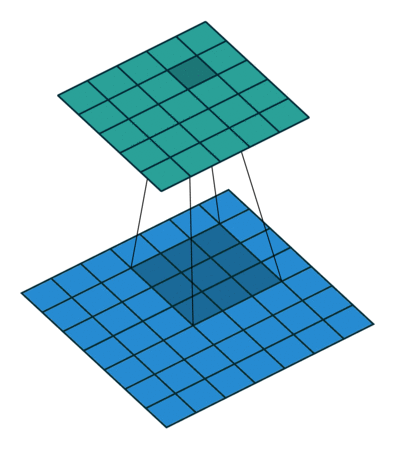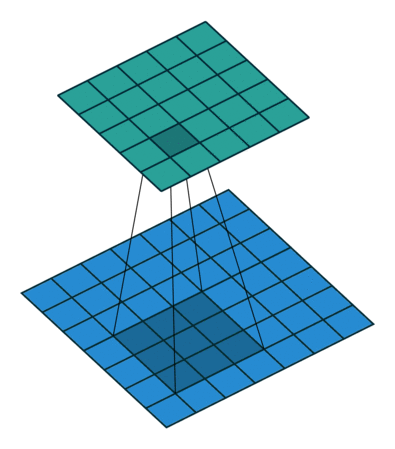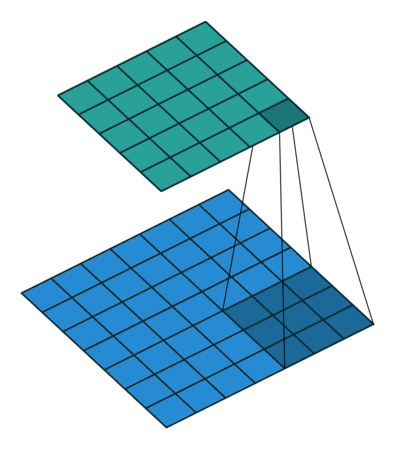
![]()
Figure 2: Convolution with kernel of size 3x3 (left) vs. Convolution with kernel of size 1x1 (right)
Global Average Pooling
In conventional convolutional neural network, the feature maps of the last convolutional layer are vectorized and fed into fully connected layers followed by a softmax logistic regression layer.
Problem of the fully-connected layers:
- Prone to overfitting and heavily depend on dropout regularization
- Difficult to interpret how the category level information from the objective cost layer is passed back to the previous convolution layer
This paper propose a global average pooling (GAP) to replace the traditional fully connected layers in CNN. The idea is to generate one feature map for each corresponding category of the classification task in the last mlpconv layer. We take the average of each feature map, and the resulting vector is fed directly into the softmax layer.
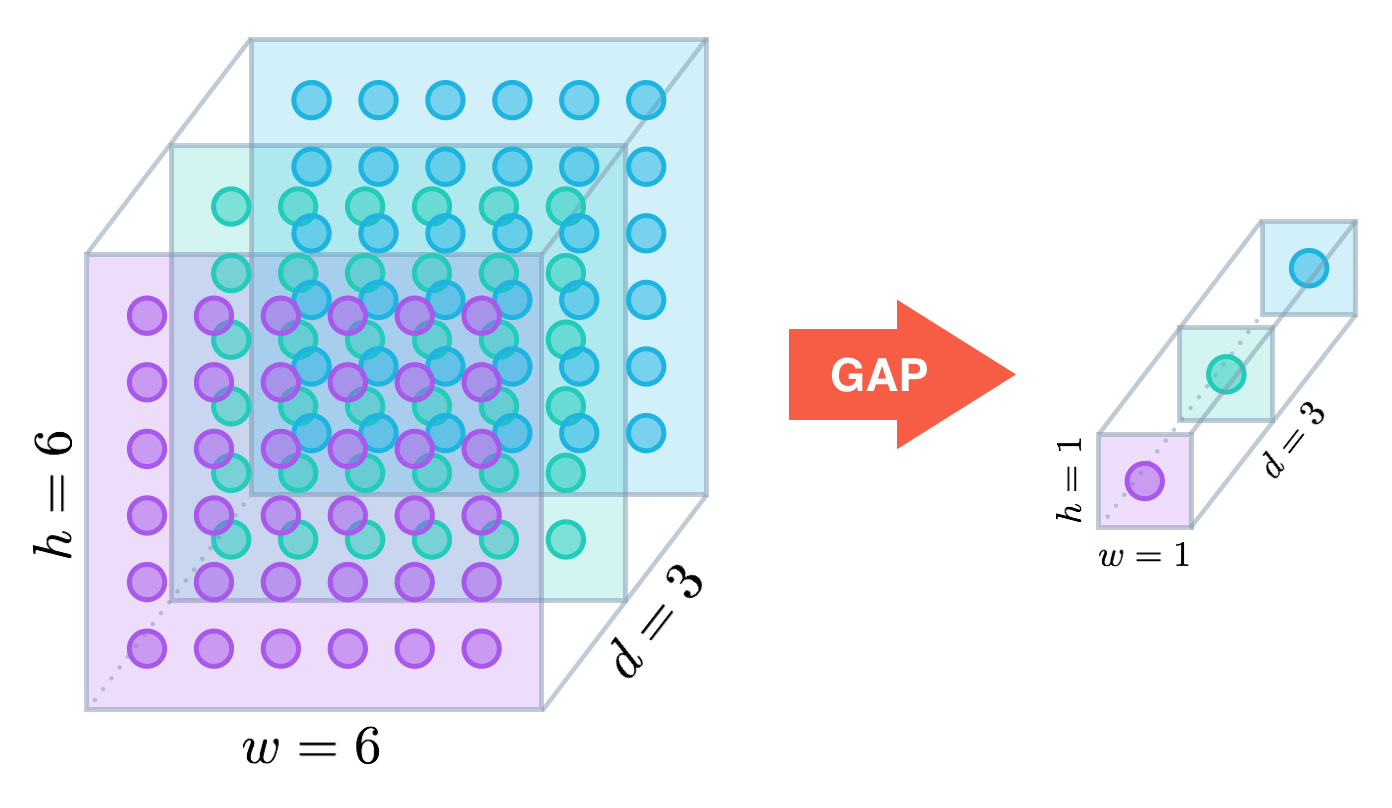 Figure 3: Example of global average pooling (GAP)
Figure 3: Example of global average pooling (GAP)
Advantage of GAP over the fully-connected layers:
- It is more native to the convolution structure by enforcing correspondences between feature maps and categories.
- Thus, the feature maps can be easily interpreted as categories confidence maps.
- There is no parameter to optimize in the global average pooling thus overfitting is avoided at this layer.
- It sums out the spatial information thus it is more robust to spatial translations of the input.
Network In Network Structure
As shown in Figure 4, the overall structure of NIN is a stack of mlpconv layers, on top of which lie the global average pooling and the objective cost layer. The number of layers in both NIN and the micro networks is flexible and can be tuned for specific tasks.
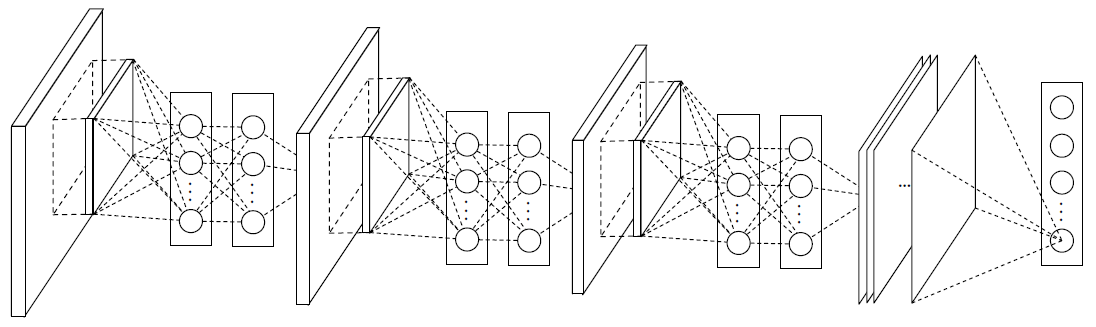 Figure 4: The overall structure of Network In Network. In this paper, the NINs include the stacking of three mlpconv layers and one global average pooling layer.
Figure 4: The overall structure of Network In Network. In this paper, the NINs include the stacking of three mlpconv layers and one global average pooling layer.



