“Harmonious Attention Network for Person Re-Identification” suggests a joint learning of soft pixel attention and hard regional attention for person re-identification tasks. It is in arxiv yet and the authors are from Queen Mary University of London and Vision Semantics Ltd.
Summary
- Problem Statement
- Existing person re-identification (re-id) methods either assume the availability of well-aligned person bounding box images as model input or rely on constrained attention selection mechanisms to calibrate misaligned images.
- They are therefore sub-optimal for re-id matching in arbitrarily aligned person images potentially with large human pose variations and unconstrained auto-detection errors.
- Research Objective
- Show the advantages of jointly learning attention selection and feature representation in a CNN by maximising the complementary information of dfferenct levels of visual attention subject to re-id discriminative learning constraints.
- Proposed Solution
- Proposed Harmonious Attention CNN (HA-CNN) model for joint learning of soft pixel attention and hard regional attention along with simultaneous optimisation of feature representations, dedicated to optimise person re-id in uncontrolled (misaligned) images.
- Contribution
- Formulate a idea of jointly learning multi-granularity attention selection and feature representation for optimising person re-id.
- Propose Harmonious Attention Convolutional Neural Network (HA-CNN) to simultaneously learn hard region-level and soft pixel-level attention.
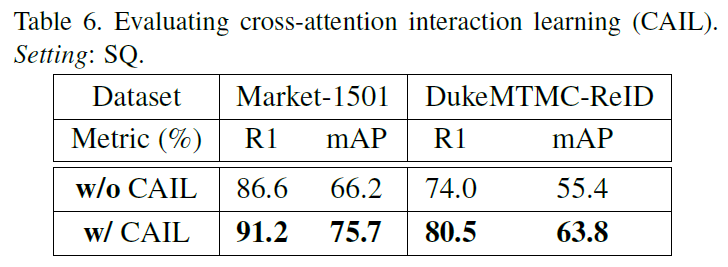
- Introduce a cross-attention interaction learning scheme for further enhancing the compatibility between attention selection and feature representation given re-id discriminative constraints.
Harmonious Attention Network
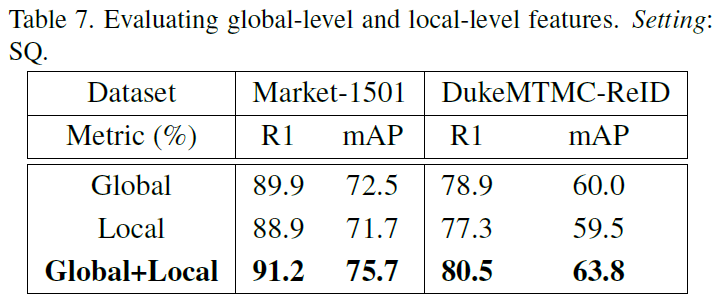
Harmonious Attention Convolutional Neural Network (HA-CNN) aims to concurrently learn a set of harmonious attention, global and local feature representations for maximising their complementary benefit and compatibility in terms of both discrimination power and architecture simplicity.
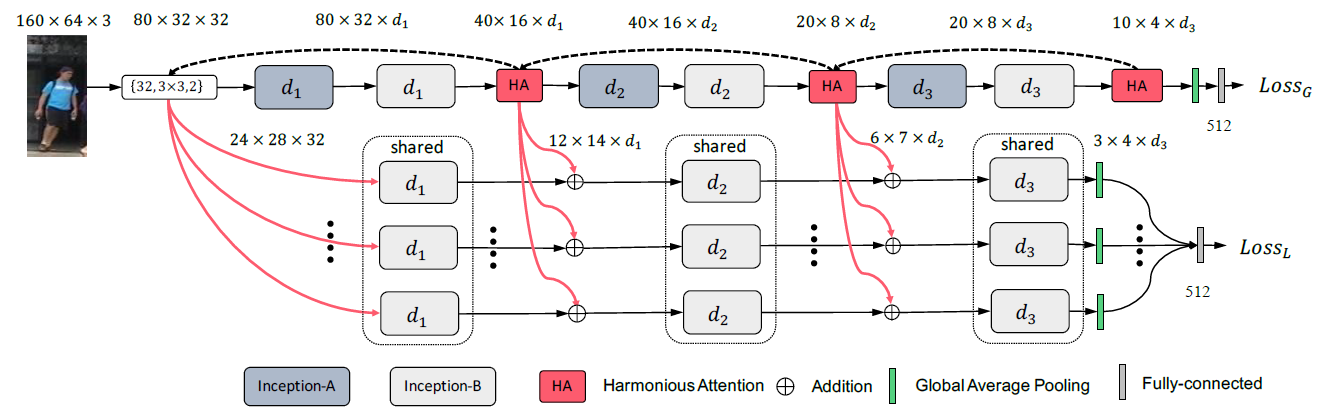
Figure 1: The Harmonious Attention Convoluntional Neural Network.
HA-CNN has multi-branch network architecture and its objective is to minimise the model complexity therefore reduce the network parameter size whilst maintaining the optimal network depth. There are two branches in HA-CNN:
- Local branch: Each stream aims to learn the most discriminative visual features for one of local image regions of a person bounding box image.
- Use three Inception-B blocks
- Every stream ends with global average pooling and one fully-connected (FC) layer
- Use cross-entropy classification
- Global branch: This aims to learn the optimal global level features from the entire person image.
- Use three Inception-A and Inception-B blocks
- The network ends with a global average pooling layer and a fully-connected (FC) layer
- Use cross-entropy classification
Harmonious Attention Learning
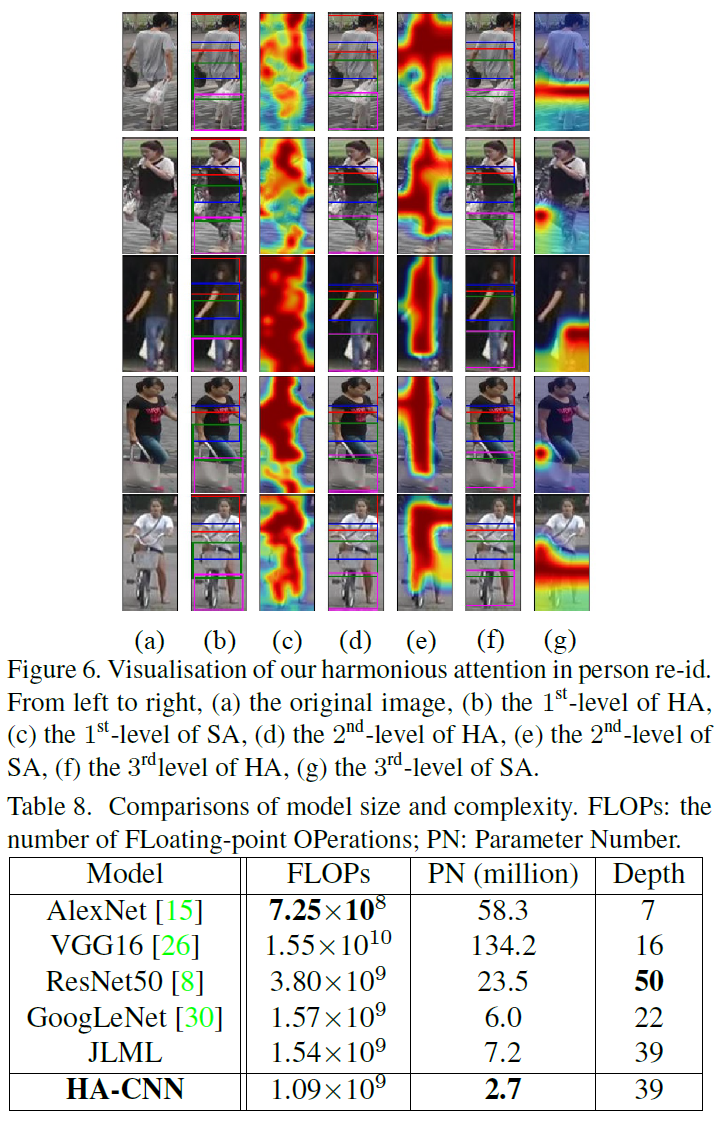
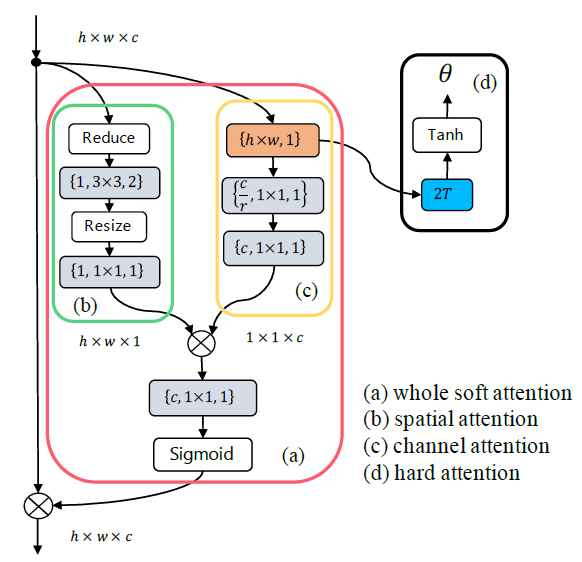 Figure 2: The structure of each Harmonious Attention module consists of (a) Soft Attention which includes (b) Spatial Attention
(pixel-wise) and (c) Channel Attention (scale-wise), and (d) Hard Regional Attention (part-wise). Layer type is indicated by background colour: grey for convolutional (conv), brown for global average pooling, and blue for fully-connected layers. The three
items in the bracket of a conv layer are: filter number, filter shape, and stride. The ReLU [15] and Batch Normalisation (BN) [10]
(applied to each conv layer) are not shown for brevity.
Figure 2: The structure of each Harmonious Attention module consists of (a) Soft Attention which includes (b) Spatial Attention
(pixel-wise) and (c) Channel Attention (scale-wise), and (d) Hard Regional Attention (part-wise). Layer type is indicated by background colour: grey for convolutional (conv), brown for global average pooling, and blue for fully-connected layers. The three
items in the bracket of a conv layer are: filter number, filter shape, and stride. The ReLU [15] and Batch Normalisation (BN) [10]
(applied to each conv layer) are not shown for brevity.
Soft Spatial-Cannel Attention
- Spatial Attention
- First, it uses global cross-channel averaging pooling layer
- \[S^l_{input}=\frac{1}{c}\sum^c_{i=1}X^l_{1:h,1:w,i}\]
- Second, it uses a conv layer of 3x3 filter with stride 2
- Channel Attention
- 4-layers squeeze-and-excitation sub-network
- It use global average pooling and two convolutional layers
- \[C^l_{input}=\frac{1}{h\times w}\sum^h_{i=1}\sum^w_{j=1}X^l_{i.j.1:c}\]
- \[C^l_{excitation}=ReLU(W^{ca}_2 \times ReLU(W^{ca}_1C^l_{input}))\]
Finally, given the largely independent nature between spatial (inter-pixel) and channel (inter-scale) attention, the authors propose to learn them in a joint but factorised way as:
\[A^l=S^l \times C^l\]Hard Regional Attention
- The hard attention learning aims to locate latent (weakly supervised) discriminative T regions/parts (e.g. human body parts).
- This regional attention is modeled by learning a transformation matrix below.
- \[A^l = \begin{bmatrix}s_h & 0 & t_x \\0 & s_w & t_y \end{bmatrix}\]
- It allows for image cropping, translation, and isotropic scaling operations by varying two scale factors (\(s_h, s_w\)) and the 2-D spatial position (\(t_x, t_y\)).
- Use pre-defined region size by sixing \(s_h\) and \(s_w\) for limiting the model complex.
- Therefore, the effective modelling part of \(A^l\) is only \(t_x\) and \(t_y\), with the output dimension as \(2 \times T\).
- The hard regional attention is enforced on that of the corresponding network block to generate T different parts which are subsequently fed into the corresponding streams of the local branch.
Cross-attention Interaction Learning
At the l-th level, the authors utilise the global-branch feature \(X^{(l,k)}_G\) of the k-th region to enrich the corresponding local-branch feature \(X^{(l,k)}_L\) by tensor addition as
\[\widetilde{X}^{(l,k)}_L = X^{(l,k)}_L + X^{(l,k)}_G\]where \(X^{(l,k)}_G\) is computed by applying the hard regional attention of the (l+1)-th level’s HA attention module.
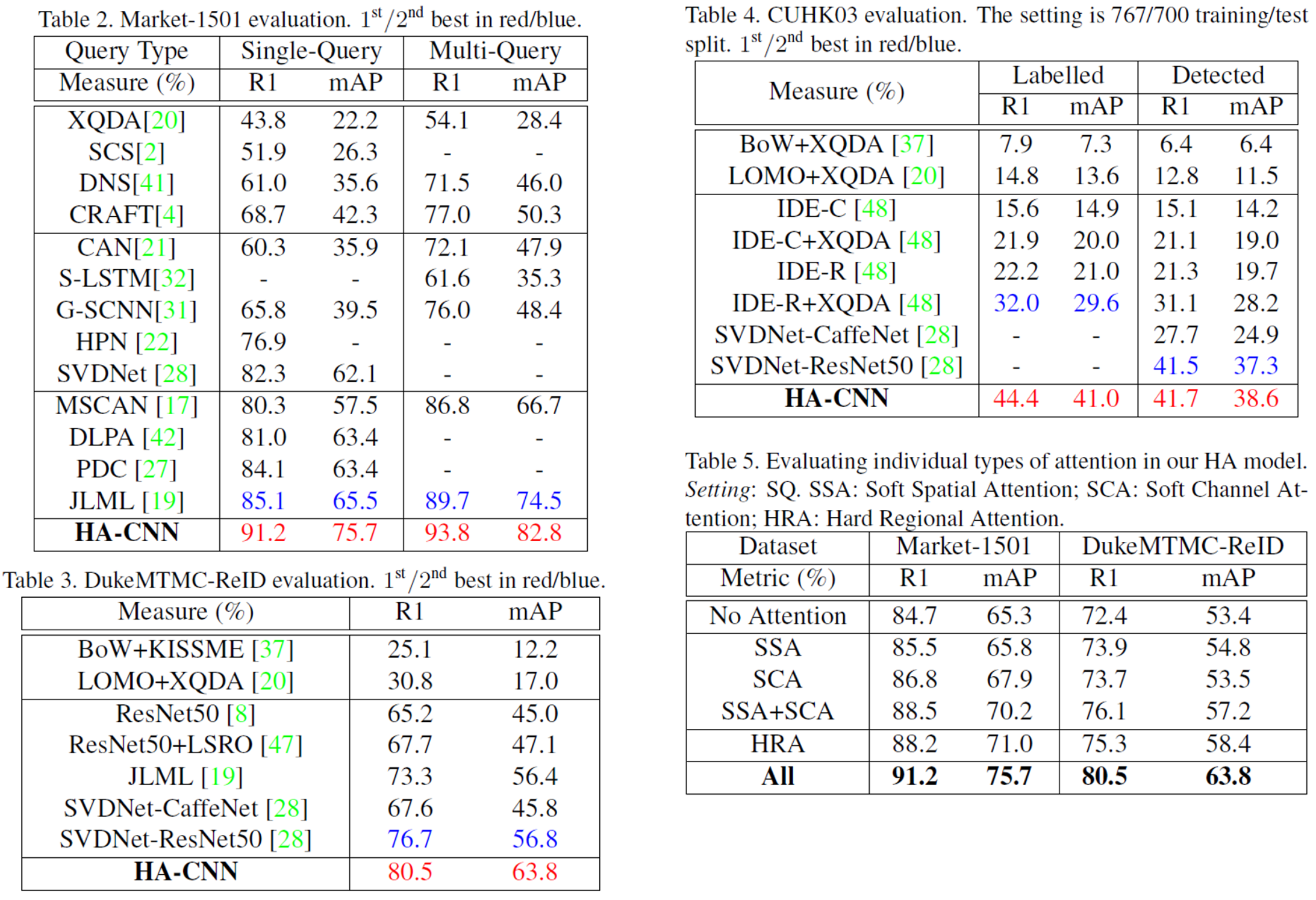
Experiments