This post is a summary and paper skimming on detection and segmentation related research. So, this post will be keep updating by the time.
Paper List
Segmentation
- Revisiting Dilated Convolution: A Simple Approach for Weakly- and Semi- Supervised semantic Segmentation, CVPR2018
- What’s the point: semantic segmentation with point supervision, ICCV2016
Detection
- Unsupervised Learning of Object Landmarks by Factorized Spatial embeddings, ICCV2016
- Scalable Deep Learning Logo Detection
Revisiting Dilated Convolution
- Title: Revisiting Dilated Convolution: A Simple Approach for Weakly- and Semi- Supervised semantic Segmentation
- Conference: CVPR2018
- Institute: UIUC, NUS, IBM, Tencent
Summary
- Problem Statement
- Time-consuming boudning box annotation is sidestepped in weakly supervised learning.
- In this case, the supervised information is restricted to binary labels (object absence/presence) without their locations.
- Research Objective
- To infer the object locations during weakly supervised learning
- Proposed Solution
- Propose a multiple-instance learning approach that iteratively trains the detector and infers the object locations in the positive training images
- Window refinement method
- Contribution
- Multi-fold multiple instance learning procedure, which prevents training from prematurely locking onto erroneous object locations
- Window refinement method improves the localization accuracy by incorporating an objectness prior.
 Figure: Multi-fold weakly supervised training
Figure: Multi-fold weakly supervised training
References
Unsupervised Learning of Object Landmarks by Factorized Spatial embeddings
- Conference: ICCV2016
- Institute: University of Oxford
Summary
- Problem Statement
- Learning automatically the structure of object categories is an oppen problem in computer vision.
- Research Objective
- To learn landmarks of objects with unsupervised approach
- Proposed Solution
- Propose a unsupervised approach that can discover and learn landmarks in object categories, thus characterizing their structure.
- Approach is based on factorizing image deformations, as induced by a viewpoint change or an object deformation, by learning a deep neural network that detects landmarks consistently with such visual effects.
- Contribution
- Learned-landmarks establish meaningful correspondences between different object instances in a category without having to impose this requirement explicitly.
- Proposed unsupervised landmarks are highly predictive of manually-annotated landmarks in face benchmark datasets, and can be used to regree these with a high degree of accuracy.
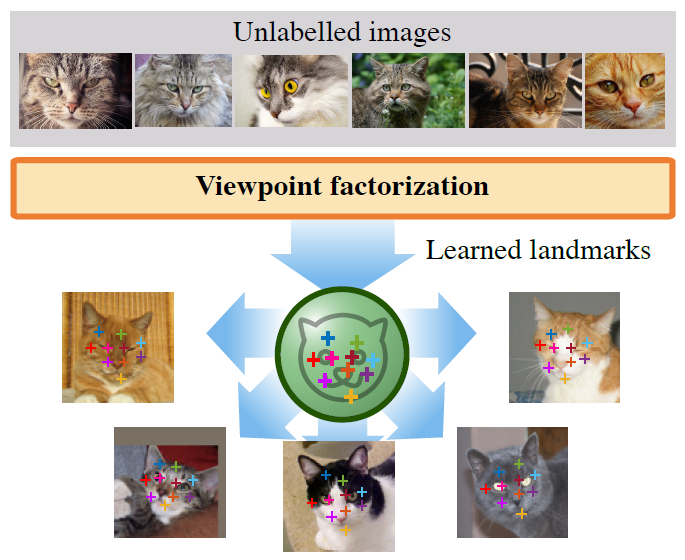 Figure: Proposed method that cna learn view point invariant landmarks without any supervision.
Figure: Proposed method that cna learn view point invariant landmarks without any supervision.
References
Scalable Deep Learning Logo Detection
- Conference: Arxiv
- Institute: Queen Mary University of London, Vision Semantics Ltd.
Summary
- Problem Statement
- Existing logo detection methods usually consider a small number of logo classes and limited images per class with a strong assumption of requiring tedious object bounding box annotations.
- This is not scalable to real-world dynamic applications.
- Research Objective
- To handle the problem by exploring the webly data learning principle without the need for exhaustive manual labelling.
- To learn scalable logo detection method
- Proposed Solution
- Propose a novel incremental learning approach, called Scalable Logo Self-co-Learning (SL2)
- It is capable of automatically self-discovering informative training images from noisy web data for progressively improving model capability in a cross-model co-learning manner.
- Contribution
- Introduce a very large (2,190,757 images of 194 logo classes) logo dataset “WebLogo-2M”
- Proposed SL2 method is superior over the state-of-the-art and weekly supervised detection and contemporary webly data learning approaches.
![]() Figure: Logo detection performance on WebLogo-2M.
Figure: Logo detection performance on WebLogo-2M.
References
What’s the point
- Title: What’s the point: semantic segmentation with point supervision
- Conference: ICCV2016
Summary
- Problem Statement
- Detailed per-pixel annotations enable training accurate models but are very time-consuming to obtain
- Image-level class labels are an order of magnitude cheaper but result in less accurate models
- Research Objective
- To take a natural step (point) from image-level annotation towards stronger supervision
- Proposed Solution
- Annotators point to an object if one exists
- Incorporate this point supervision along with a novel objectness potential in the training loss function of a CNN model.
- Contribution
- Experimental results on the PASCAL VOC 2012 benchmark reveal that the combined effect of point-level supervision and objectness potential yields an improvement of 12.9% mIOU over image-level supervision
- Models trained with point-level supervision are more accurate than models trained with image-level, squiggle-level or full supervision given a fixed annotation budget
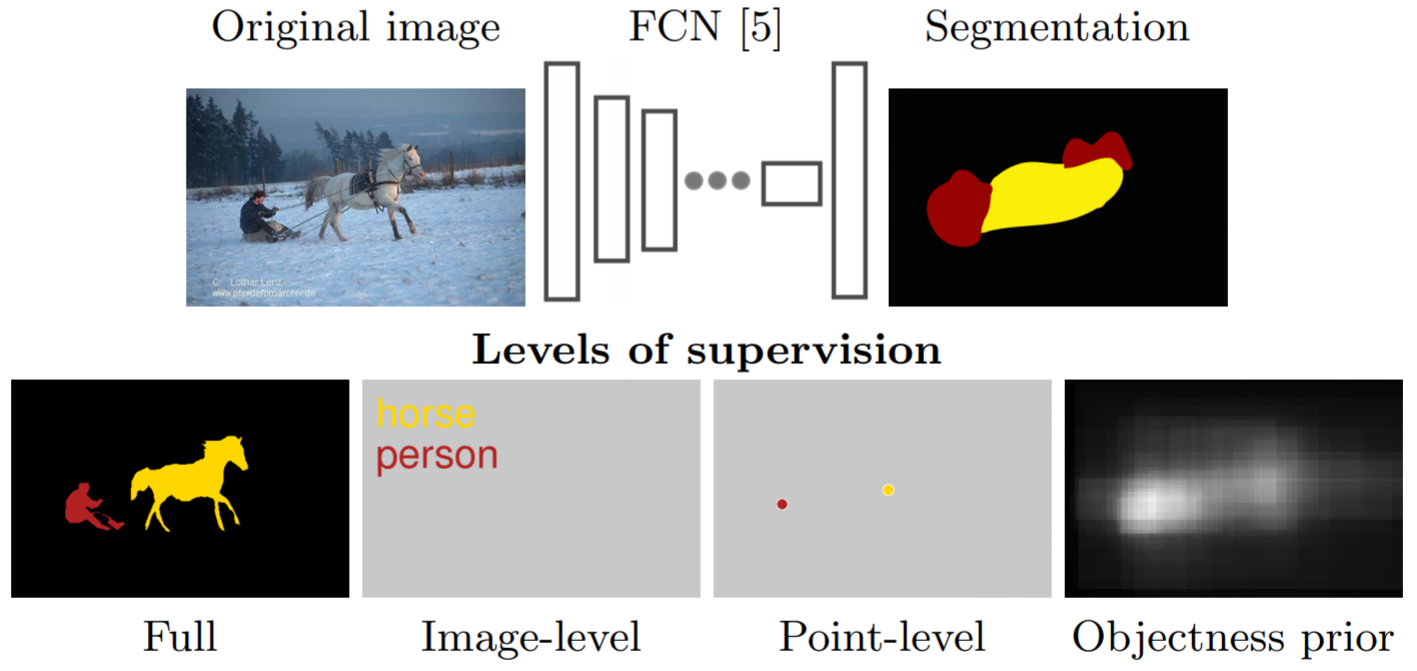 Figure:(Top): Overview of our semantic segmentation training framework. (Bottom): Different levels of training supervision
Figure:(Top): Overview of our semantic segmentation training framework. (Bottom): Different levels of training supervision



